Text Mining
Joffrey JOUMAA
25 February 2023
![]()
1 Chargement des packages
# packages
library(data.table)
library(ggplot2)
library(igraph)
library(ggraph)
library(SnowballC)
library(tm)
library(tidytext)
library(grid)
library(gridBase)
library(gtable)
library(RCurl)
library(wordcloud)
library(RColorBrewer)
library(gridExtra)
library(widyr)
library(knitr)
library(DT)
library(dplyr)
library(topicmodels)
library(shiny)
# espace de travail
# setwd("C:\\Users\\M17DC00\\Documents\\analysis\\relance\\textmining")
# chemin d'accès à Java
#Sys.setenv(JAVA_HOME="C:/Program Files/Java/jre1.7.0_25/")
# enlève la notation scientifique
options(scipen=999)2 Chargement d’un jeu de données
Ce jeu de données correspond uniquement aux relances appels sur formulaire des clients de 2017. Il m’a été fournit par Nolwenn, qui l’a extrait via SAS.
# chargement du jeu de données
datasetRaw = fread("./data/relance appel sur formulaire.csv",
encoding = "UTF-8")3 Pré-traitement du jeu de données
3.1 Sélection des variables pertinentes
# sélection des colonnes pertinentes
dataset = datasetRaw[,.(DT_RCP,
DT_ENR,
HR_ENR,
DOMAINE,
FAMILLE,
OBJET,
MOTIF,
COMMENTAIRE_ENR,
COMMENTAIRE_TRT)]3.2 Format date
Pour faciliter l’emploi d’un filtre sur le délai entre la date de réception de la demande et la date de la relance nous permettant d’identifier les relances de premier niveau, je fusionne la date et l’heure d’enregistrement, que j’appelle DT_ENR (pour la date d’enregistrement de la relance) et j’extrais la date de réception du premier contact, de la zone de commentaire enregistrement COMMENTAIRE_ENR, que j’appelle DT_RCP. J’appelle date, le format suivant %d-%m-%Y %HH:%MM:%SS.
# extraction de la date de réception du premier contact
dataset[, `:=` (HR_ENR = NULL,
DT_ENR = as.POSIXct(paste(DT_ENR, HR_ENR),
format = "%d/%m/%Y %H.%M.%S"))]# fusion de DT_ENR et HR_ENR
dataset[, DT_RCP := as.POSIXct(substr(COMMENTAIRE_ENR, 22, 37),
format = "%d/%m/%Y %H:%M")]4 Analyses
4.1 Délai
Je calcule le délai entre la date d’enregistrement de la relance et la date de réception du premier contact.
# calcul du délais par relance
dataset[, delay := difftime(DT_ENR, DT_RCP, units = "hours")]Puis je regarde la distribution des délais.
# histogram du temps de délais entre le premier contact et une relance
ggplot(dataset, aes(x = delay)) +
geom_histogram(aes(y = ..density..),
colour = "black",
fill = "white") +
labs(x = "Délais en heures") +
geom_density(fill="blue", alpha=0.3)+
geom_vline(aes(xintercept = 24),
color="red", linetype="dashed", size=1) 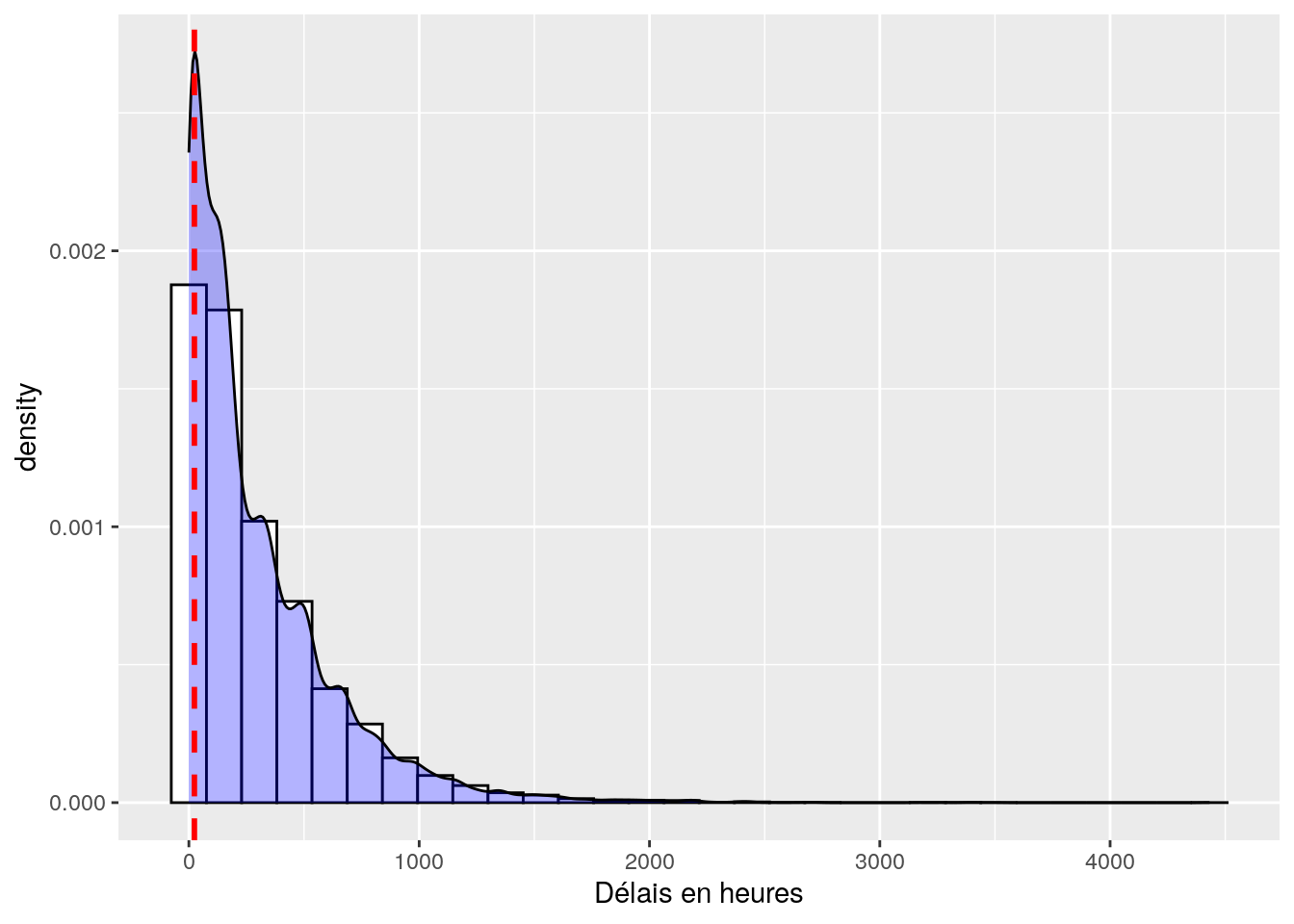
Figure 4.1: Distribution des temps de délais. Le trait en pointillé correspond à notre limite des 24 heures.
Comme rien ne semble se dégager, je fais un zoom sur les délais compris dans la première semaine du premier contact, i.e 0 < delay < 7 * 24.
# histogram du temps de délais entre le premier contact et une relance
ggplot(dataset, aes(x = delay)) +
geom_histogram(aes(y = ..density..),
binwidth = 5,
colour = "black",
fill = "white") +
scale_x_continuous(limits = c(0, 168)) +
scale_y_continuous(limits = c(0, 0.0125)) +
labs(x = "Délais en heures") +
geom_density(fill="blue", alpha=0.3)+
geom_vline(aes(xintercept = 24),
color="red", linetype="dashed", size=1) 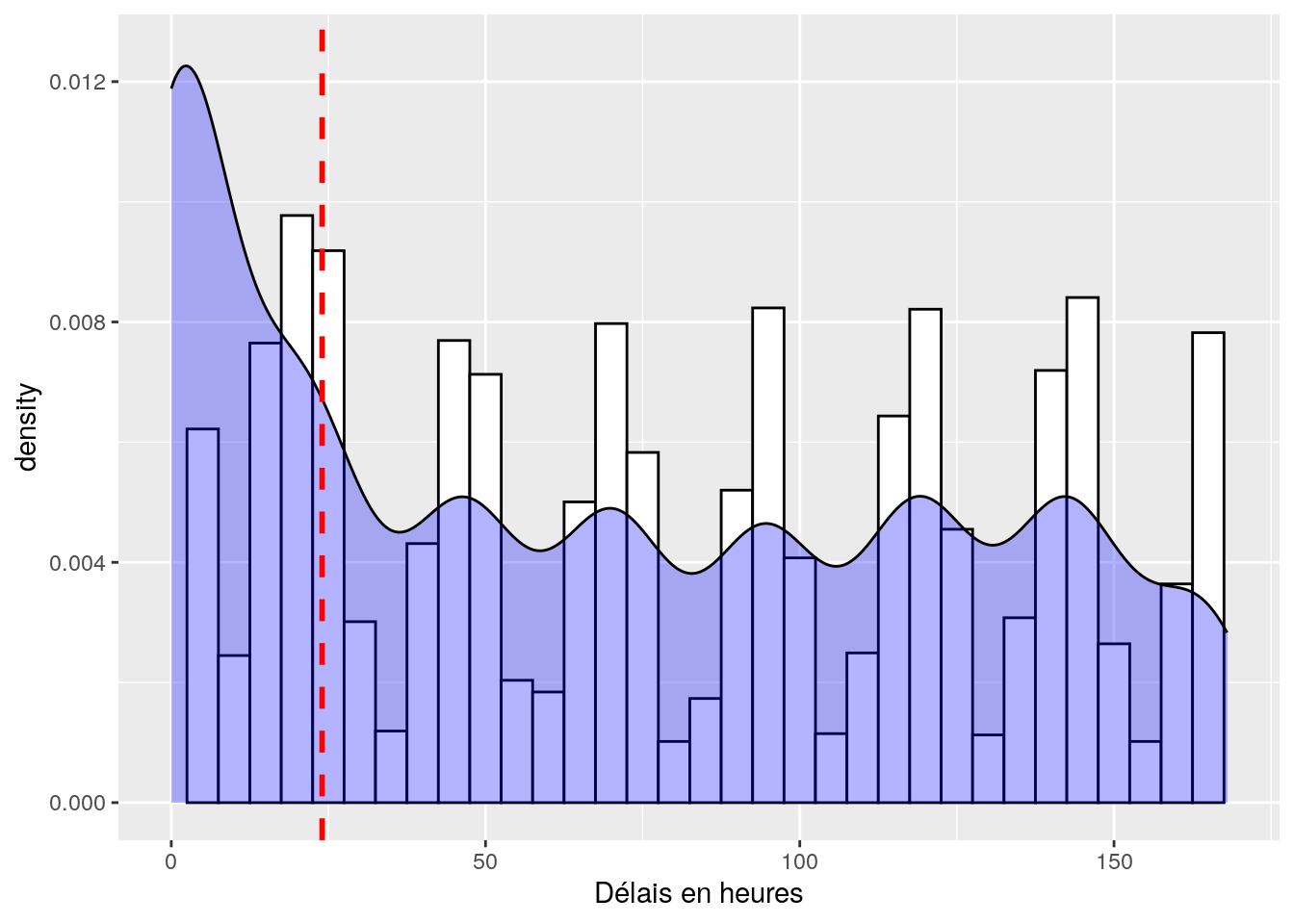
Figure 4.2: Distribution des temps de délais allant jusqu à une semaine. Le trait en pointillé rouge correspond à notre limite des 24 heures.
A la lecture de ce graphique, je me dis qu’une limite à 35 heures serait peut être plus adaptée…
# histogram du temps de délais entre le premier contact et une relance
ggplot(dataset, aes(x = delay)) +
geom_histogram(aes(y = ..density..),
binwidth = 1,
colour = "black",
fill = "white") +
scale_x_continuous(limits = c(0, 168)) +
scale_y_continuous(limits = c(0, 0.0125)) +
labs(x = "Délais en heures") +
geom_density(fill="blue", alpha=0.3)+
geom_vline(aes(xintercept = 24),
color="red", linetype="dashed", size=1) +
geom_vline(aes(xintercept = 35),
color="green", linetype="dashed", size=1) 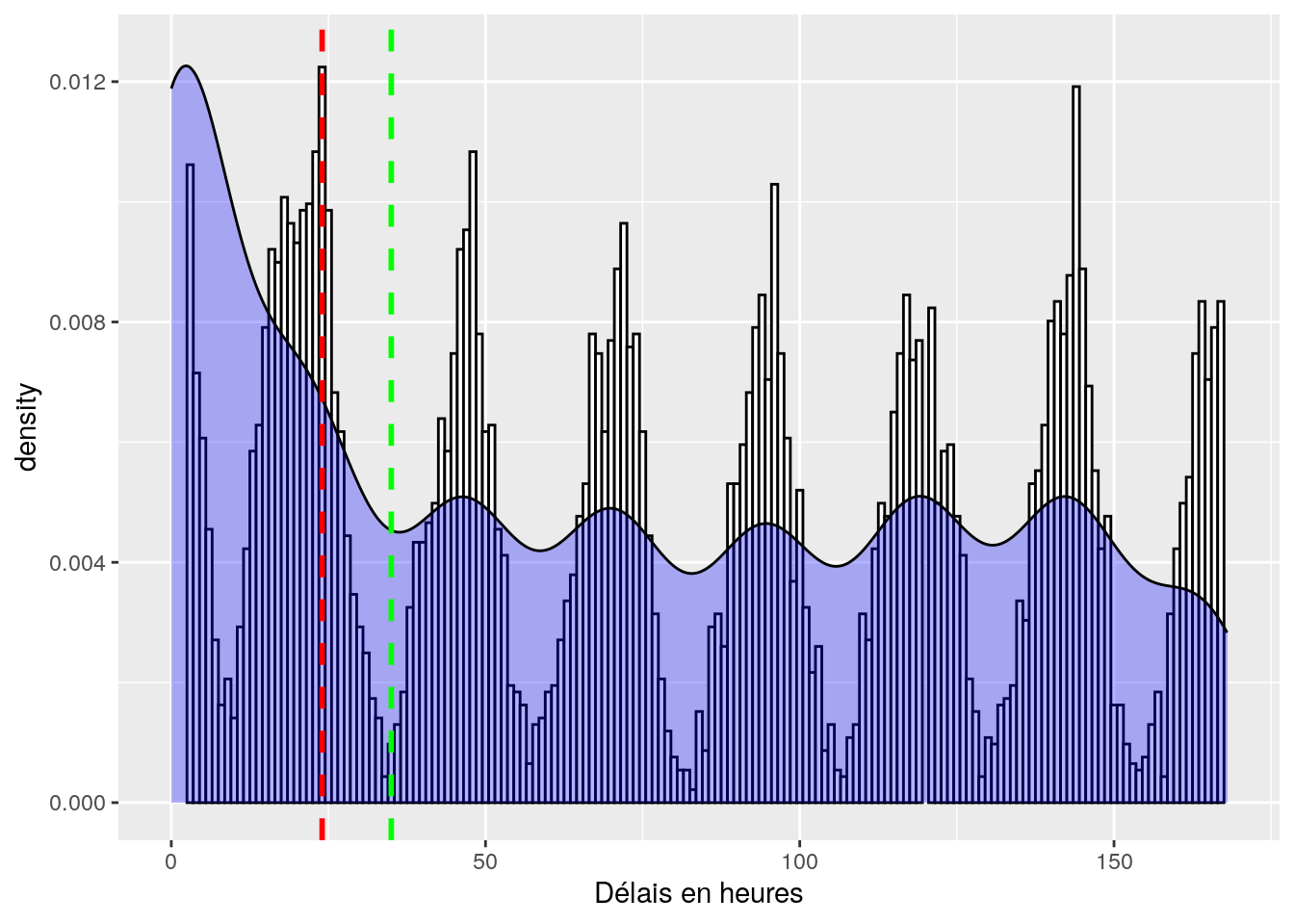
Figure 4.3: Distribution des temps de délais allant jusqu a une semaine. Le trait en pointillé rouge correspond à notre limite des 24 heures et celui en vert a une limite de 35 heures.
… ou peut être encore plus faible, compte tenu de la première bar. Ici, on a donc décidé de choisir une limite à 35 h.
4.2 Nettoyage pour Text Mining
Dans un premier temps on ne sélectionne que les relances ayant eu lieu dans les 35 heures suivant le premier contact. Ici, je ne fais pas de filtre sur les domaines ou les familles, toutes les relances sont donc considérées. Je rajoute également une colonne pour numéroter les relances.
# sélection des relances en foncition du délai choisi
dataset1NV = dataset[delay < 35, ]
# numérotation des relances de premier niveau
dataset1NV[, relance := 1:.N]Puis, je traite directement dans les commentaires la référence au mot “heure”, que l’on trouve souvent notée “h” lorsqu’un délai est énoncé (“24 h” ou “48h”). Le problème vient du fait que l’on peut parfois rencontrer un “h” séparé par un espace du temps annoncé. Lorsque je supprime par la suite les stop-words, le “h” est alors supprimé, ce qui nous fait perdre de l’information liée aux délais. Pour palier ce cas particulier, j’ai décidé de tout simplement coller le “h” au temps qui le précède de façon à obtenir un seul et même format qui ne sera ensuite pas supprimé.
# lorsque "h" est rencontré tout seul, je supprime simplement l'espace le précédent
dataset1NV[,COMMENTAIRE_TRT:=gsub(" h ",
"h ",
COMMENTAIRE_TRT,
ignore.case = TRUE)]Autre cas particulier, le mot “jour”, qui peut prendre plusieurs formes. Cette étape a été faite a posteriori en important le dictionnaire réalisé un peu après. A la suite de cette étape, à chaque fois que le mot “jour”, sous toutes ses formes, est précédé d’un chiffre, celui-ci est automatiquement transformé sous la forme “Xjour”, où X est le chiffre qui le précede, peu importe qu’il y ai un espace entre la forme du mot “jour” et le chiffre.
# importation du dictionnaire
dictionnaire = fread("./data/dictionnaire.csv", encoding = "UTF-8")
# construction de l'expression régulière visant à identifier toutes les formes du mot "jour", le résultat est : "jour|jrs|j|jours|jr"
regexpJour=substr(dictionnaire[trad=="jour",paste0(word,"|",collapse="")],
1,
nchar(dictionnaire[trad=="jour",paste0(word,"|",collapse="")])-1)
# remplacement des formes avec un espace
dataset1NV[,COMMENTAIRE_TRT:=gsub(paste0("(\\d)(\\s)(",regexpJour,")",
collapse=""),
"\\1jour",
COMMENTAIRE_TRT,
ignore.case = TRUE)]
# exemple
gsub("(\\d)(\\s)(jour|jrs|j|jours|jr)", "\\1jour", c("dans 10 jrs il y aura 20 j de plus qu'il y a 10 jours"))[1] "dans 10jour il y aura 20jour de plus qu'il y a 10jour"# remplacement des formes sans un espace
dataset1NV[,COMMENTAIRE_TRT:=gsub(paste0("(\\d)(",regexpJour,")",collapse=""),
"\\1jour",
COMMENTAIRE_TRT,
ignore.case = TRUE)]
# exemple
gsub("(\\d)(jour|jrs|j|jours|jr)", "\\1jour", c("dans 10jrs il y aura 20j de plus qu'il y a 10jours"))[1] "dans 10jour il y aura 20jour de plus qu'il y a 10jour"Puis, j’isole tous les mots de la zone de commentaire COMMENTAIRE_TRT.
# isolation de chacun des mots présents dans la zone de commentaire
dataset1NVtidy = unnest_tokens(dataset1NV, word, COMMENTAIRE_TRT, drop = FALSE)4.2.1 isoler un commentaire avec un mot
Petite interlude pour chercher à expliciter des mots avec les commentaires associés. Attention toutefois, lorsque l’on cherche un mot qui a été “traduit” par notre dictionnaire, il faut rechercher le mot original et non la traduction. Par exemple “toujourspas” a été traduit par “toujours pas”. Pour rechercher le commentaire faisant mention de ce terme, il faut donc chercher le mot “toujourspas” et non sa traduction.
# le tableau qui va bien
datatable(caption = "Liste des commentaires présents dans le jeu de données.",
dataset1NV[,.(Commentaire = tolower(COMMENTAIRE_TRT),
`Délais (h)` = round(delay,2),
Relance = relance)],
options = list(
columnDefs = list(list(targets = c(1, 2), searchable = FALSE)),
pageLength = 10
),
rownames = FALSE)Ci-dessous une fonction faisant la même chose, mais en mieux !
# fonction pour isoler un ou des commentaires en faisant une recherche sur l'un des mots qui le compose
relan = function(txt,nb=1,exact=TRUE){
# indice des commentaires en se basant sur les mots ou leur traduction
if (isTRUE(exact)){
ind = dataset1NVtidy[word==txt,relance]
} else {
ind = dataset1NVtidy[trad==txt,relance]
}
# choix aléatoire des commentaires
if (nb < length(ind)){
ind.random = sample(ind, nb)
} else if (length(ind)!=1){
ind.random = sample(ind, length(ind))
} else {
ind.random = ind
}
# on retourne les commentaires
return(as.list(dataset1NV[relance %in% ind.random, .(commentaire = tolower(COMMENTAIRE_TRT))]))
}4.2.2 Dictionnaire
Ici, on va dans un premier temps exporter tous les mots présents au moins une fois dans notre jeu de données. On va ensuite ouvrir ce fichier sous word pour corriger les fautes d’orthographe et traduire les acronymes. Le fichier des mots “traduits” est ensuite réimporté pour constituer un dictionnaire (mot => traduction, ./data/dictionnaire.csv) qui est ensuite exporté pour une (probable) future utilisation.
# liste des mots à traiter manuellement
write.csv2(dataset1NVtidy[,.(word=unique(word))],"./data/wordsNonCorrected.csv",row.names = F)
# # importation des mots corrigée sous word
# trad=read.csv2("./data/wordsCorrected.csv",
# stringsAsFactors = FALSE)
#
# # création d'un dictionnaire
# dictionnaire = dataset1NVtidy[,.(word=unique(word),
# trad=trad)]
#
# # exportation de notre dictionnaire
# write.csv2(dictionnaire,
# "./data/dictionnaire.csv",
# row.names = F)
# ici on charge directement le ditionnaire
# dictionnaire = fread("./data/dictionnaire.csv", encoding = "UTF-8")
# traduction des mots contenu dans notre corpus
setkey(dictionnaire, word) # le mot clés pour fusionner
setkey(dataset1NVtidy, word) # le mot clés pour fusionner
dataset1NVtidy = merge(dataset1NVtidy,
dictionnaire,
all = TRUE)
dataset1NVtidy = dataset1NVtidy[!is.na(DOMAINE), ][is.na(trad), trad := word]Comme certaine traductions peuvent contenir deux mots, comme par exemple "toujourspas" = "toujours pas", je relance la fonction unnest_tokens de façon à bien obtenir une ligne = un mot.
# isolation de chacun des mots présents dans la traduction
dataset1NVtidy = unnest_tokens(dataset1NVtidy, trad, trad)4.2.3 Un premier ménage (uniformité)
Ici, j’ai essayé de supprimer tous les pronoms et conjonction comprimés type “l’” ou “qu’”, mais également tous les mots avec des chiffres en prenant soin de ne pas supprimer les mots de la forme “Xjour” ou “Xh”, qui sont des références au temps pouvant nous être utiles par la suite.
# suppression des lignes avec ou moins un chiffre présent dans le mot (exception faite de Xh et Xjour, où X est un chiffre ou un nombre)
dataset1NVtidy = dataset1NVtidy[! trad %like% "[0-9]" |
trad %like% "(\\d)jour$" |
trad %like% "(\\d)h$",]
# suppression des pronoms et conjonctions comprimés (en fait lorsqu'il y a une apostrophe, je ne garde que ce qu'il y a après)
dataset1NVtidy[trad != "aujourd'hui", trad:=gsub("^(.*[\\\'])", "", trad, ignore.case = TRUE)]4.2.4 Stop-words
Je supprime ensuite les stop-words, ce sont des mots qui n’apportent pas de sens lors de l’analyse lexicale d’un texte. J’ai trouvé une liste de stop-words (non-exhaustive) qui me semble plutôt complète (https://github.com/stopwords-iso/stopwords-fr/blob/master/stopwords-fr.txt). Peut être un peu trop d’ailleurs, j’en ai supprimé quelques qui peuvent nous intéresser à l’image du mot “aujourd’hui”. Je l’ai également un peu enrichi.
# chargement de la liste de stop-words
stopWords1 = fread("./data/stopwords.txt",
header = FALSE,
col.names = "trad",
encoding = "UTF-8")
# fusion de cette liste avec celle proposée par le package `tm`
stopWords2 = data.table(trad = stopwords(kind = "fr"))
stopWords = stopWords2[stopWords1, ,on = "trad"]
# suppression des stopwords dans notre jeu de données
dataset1NVtidy = dataset1NVtidy[!stopWords, ,on = "trad"]Voici donc la liste des mots utilisés qu’il reste, rangés par nombre d’occurrences.
dataset1NVtidy[,.(n=.N),by=trad][order(-n)]4.2.5 Un second ménage (mots parasites)
Ici, on voit qu’un certain nombre de mots ne vont sûrement pas nous être utile. Je propose donc d’enlever les mots suivants : “madame”, “bonjour”, “cordialement”, “monsieur”, “demande”, “faire”, “souhaite”, “savoir”.
# liste des mots que je supprime
rmWord=data.table(words=c("madame", "bonjour", "cordialement", "monsieur", "demande", "faire", "souhaite", "savoir"))# suppression des mots "parasites"
dataset1NVtidy = dataset1NVtidy[! trad %in% rmWord$words]On peut alors faire ce type de représentation :
# bidouille...
dataPlot = setorder(dataset1NVtidy[,.(n=.N),by=trad][order(n) & n > 500], n)
dataPlot$trad = factor(dataPlot$trad, levels = dataPlot$trad)
# plot
ggplot(dataPlot,
aes(trad, n)) +
geom_bar(stat="identity")+
xlab(NULL)+
coord_flip()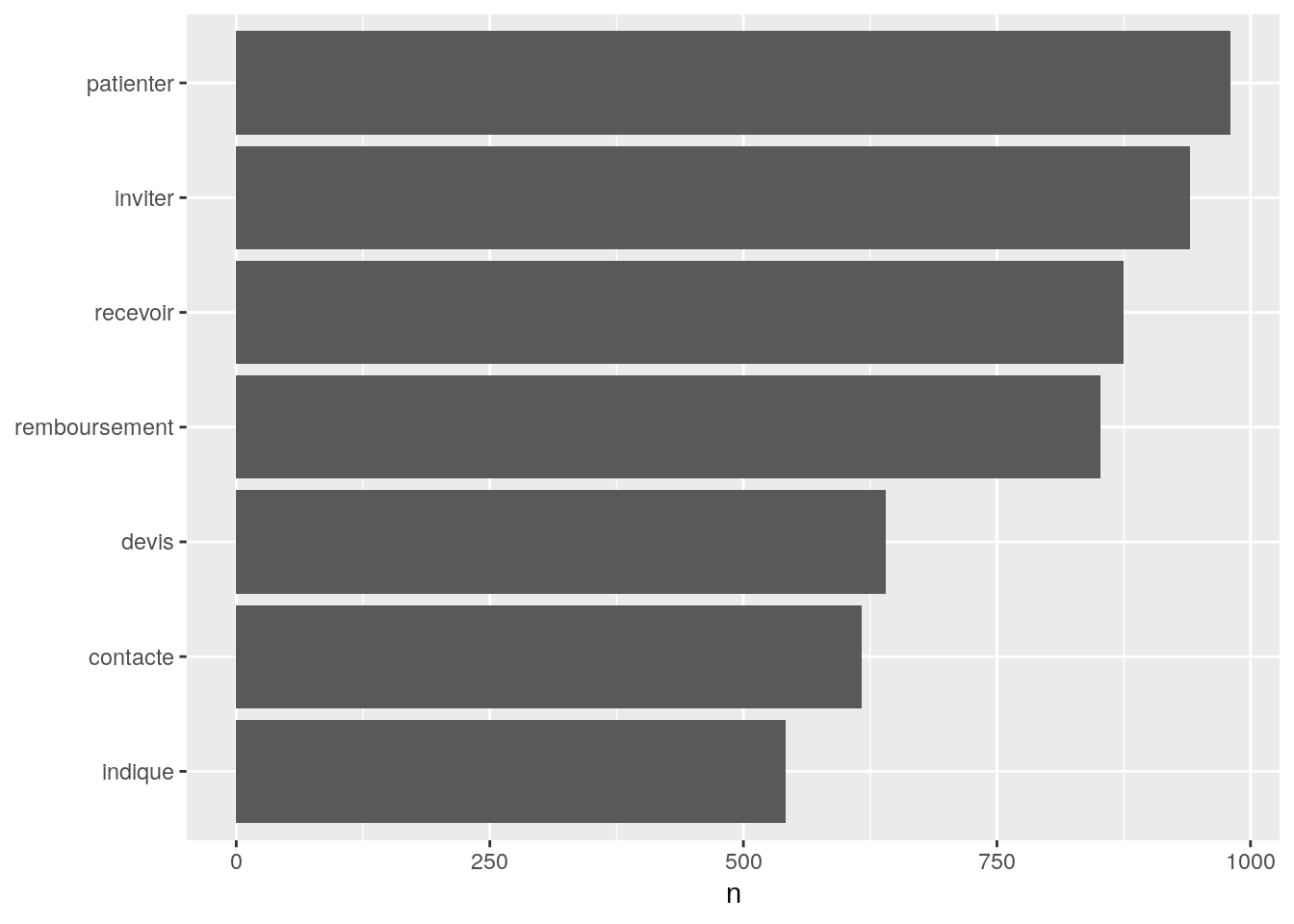
Figure 4.4: Nombre d’occurrences des mots les plus communément rencontrés
Regardons par grand domaine.
# bidouille...
dataPlot = setorder(dataset1NVtidy[,.(n=.N),by=.(trad,DOMAINE)], n)
dataPlot = dataPlot[,tail(.SD,20),by=DOMAINE]
# liste des mots à supprimer
listWord=c("affiliation", "sociale", "sécurité", "affilier", "une", "un", "veut", "espace", "toutm", "contacte", "indique", "indiqué", "informé"," suite", "contrat" ,"oui", "confirme", "souhaité", "procéder", "arrive", "passe", "jour", "naissance", "rib", "enfant","maj", "fille","attestation", "acte", "obligatoire", "portabilité", "caractère", "cms", "droits", "remboursement", "devis", "facture", "décompte", "dentaire", "estimation", "invalidité", "ij", "rente", "dossier", "paiement", "date", "connecter", "client", "revisite", "accès", "impossible", "présinscription", "compte", "message", "identifiant", "ko", "accéder", "justificatifs", "tiers", "payant")
# bonjour, j'ai confirmer à mme que l'on avait bien receptionner son devis je l'invite à patienter 48h ouvrés pour avoir l'estimation du rmbt par mail cdlt. 0.49 10
# plot
plotList=list()
for (i in dataPlot[,unique(DOMAINE)]){
plotList[[i]]=ggplot(dataPlot[DOMAINE==i,][,col:= trad %in% listWord],
aes(x = trad,
y = n,
fill = col,
col = col)) +
scale_fill_manual(values=c("grey","white"))+
scale_color_manual(values=c("grey","red"))+
geom_bar(stat="identity")+
scale_x_discrete(limits = dataPlot[DOMAINE==i,trad])+
xlab(NULL)+
theme(legend.position = "none",
axis.text.y = element_text(colour=ifelse(dataPlot[DOMAINE==i,trad] %in% listWord,"red","black")))+
coord_flip()+
facet_grid(DOMAINE~.)
}
do.call(grid.arrange,plotList)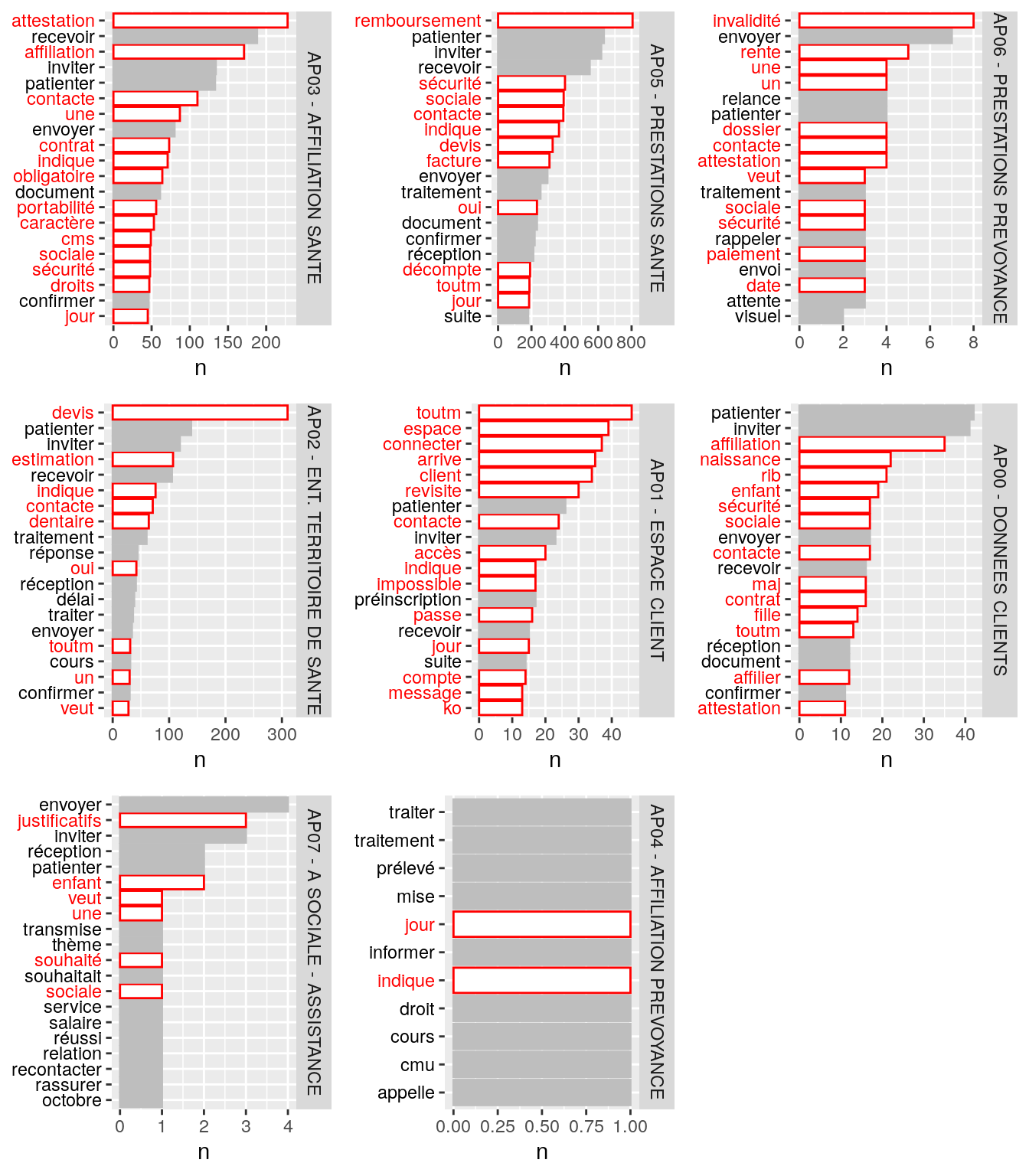
Figure 4.5: Nombre d’occurrences des mots les plus communément rencontrés par grand domaine avant suppression des mots parasites en rouge
Et maintenant en supprimant les mots parasites identifiés.
# suppression des mots parasites
dataset1NVtidy = dataset1NVtidy[! trad %in% listWord,]
# bidouille...
dataPlot = setorder(dataset1NVtidy[,.(n=.N),by=.(trad,DOMAINE)], n)
dataPlot = dataPlot[,tail(.SD,20),by=DOMAINE]
# plot
plotList=list()
for (i in dataPlot[,unique(DOMAINE)]){
plotList[[i]]=ggplot(dataPlot[DOMAINE==i,],
aes(x = trad,
y = n)) +
geom_bar(stat="identity")+
scale_x_discrete(limits = dataPlot[DOMAINE==i,trad])+
xlab(NULL)+
coord_flip()+
facet_grid(DOMAINE~.)
}
do.call(grid.arrange,plotList)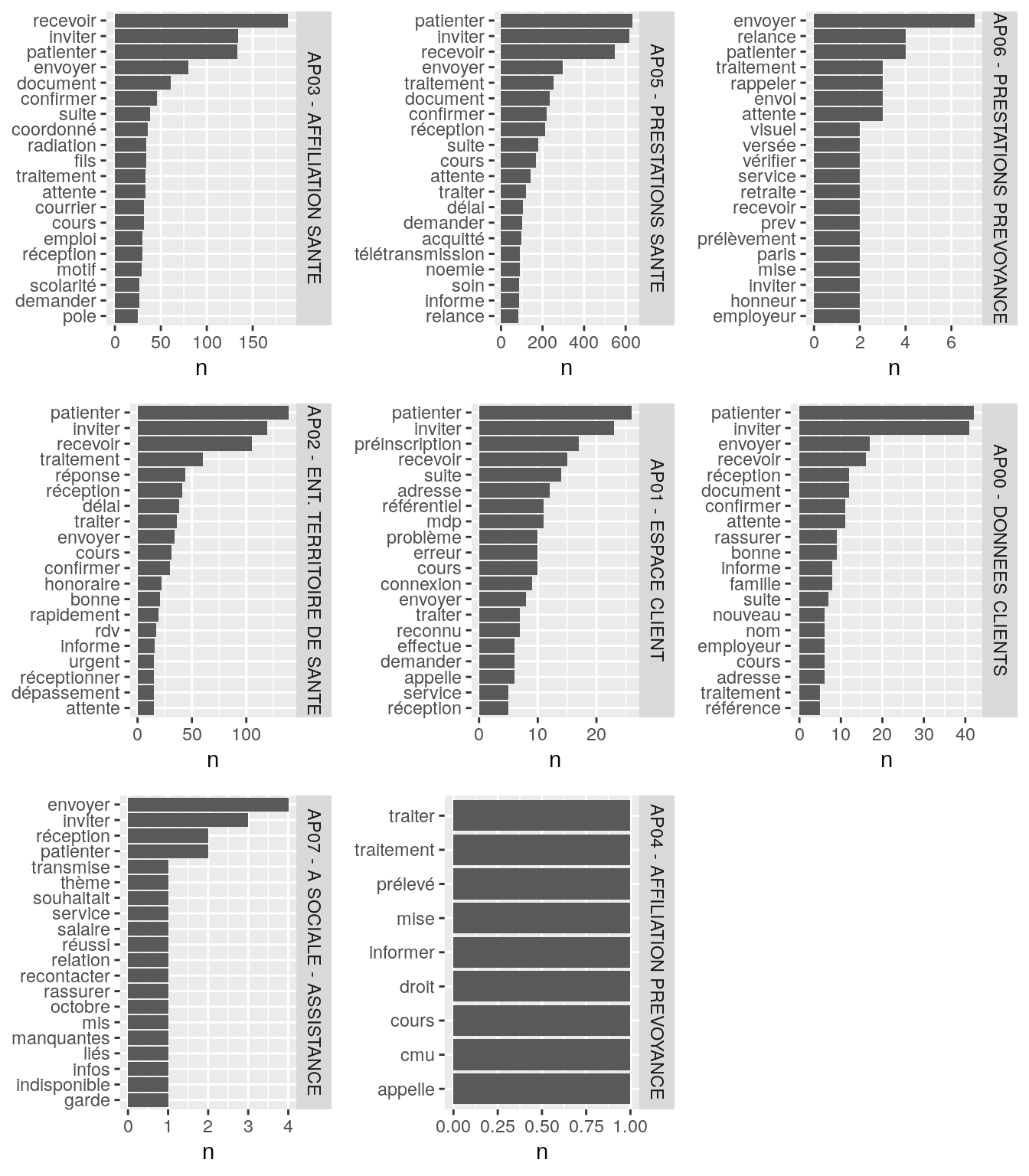
Figure 4.6: Nombre d’occurrences des mots les plus communément rencontrés par grand domaine après suppression des mots parasites
4.2.6 Racinisation
Ici j’ai fait le choix d’utiliser la méthode dite de “racination”, car elle est plus simple que la “lemmatisation”, qui nécessite elle, l’installation de logiciels supplémentaires, parfois obscure… En bref :
- Racinisation : on cherche à identifier la racine d’un mot. Elle ne fait pas foorcément sens par-elle-même, ce n’est pas un mot réel. La racine est en effet dépouillée de ses préfixes et suffixes.
- Lemmatisation : on regroupe les mots selon leur lemme, c’est à dire l’unité lexical unique et autonome. “Ainsi, un lemme correspond à la plus petite unité lexicale faisant sens, qui est souvent l’équivalent de la plus petite unité pouvant constituer une entrée dans le dictionnaire.”1
# racination
dataset1NVtidy[,stem := wordStem(trad, language = "french")]4.2.7 Analyse de sentiment
Ici, on peut attribuer un sentiment à un mot. Pour cela il existe plusieurs techniques, mais par soucis de rapidité, j’ai utilisé celle du lexique. Il s’agit d’un lexique que j’ai téléchargé qui associe à toute une liste de mot un sentiment et une polarité positive ou négative.2
# chargement du lexique
sentDict = fread("./data/lexique_sentiment.csv", encoding = "UTF-8")
sentDict[, trad := word]
# ajout de la "valeur" des mots
dataPlot = sentDict[dataset1NVtidy, , on = "trad"]
# plot 1
ggplot(dataPlot[DOMAINE %in% unique(dataPlot$DOMAINE)[1:4],],
aes(x = polarity,
fill = polarity)) +
geom_bar()+
geom_text(aes(label = paste(round((..count..)/ sapply(PANEL, FUN=function(x) sum(count[PANEL == x])) * 100), "%")), stat= "count", vjust = -.5) +
facet_grid(.~DOMAINE)+
theme(legend.position = "top")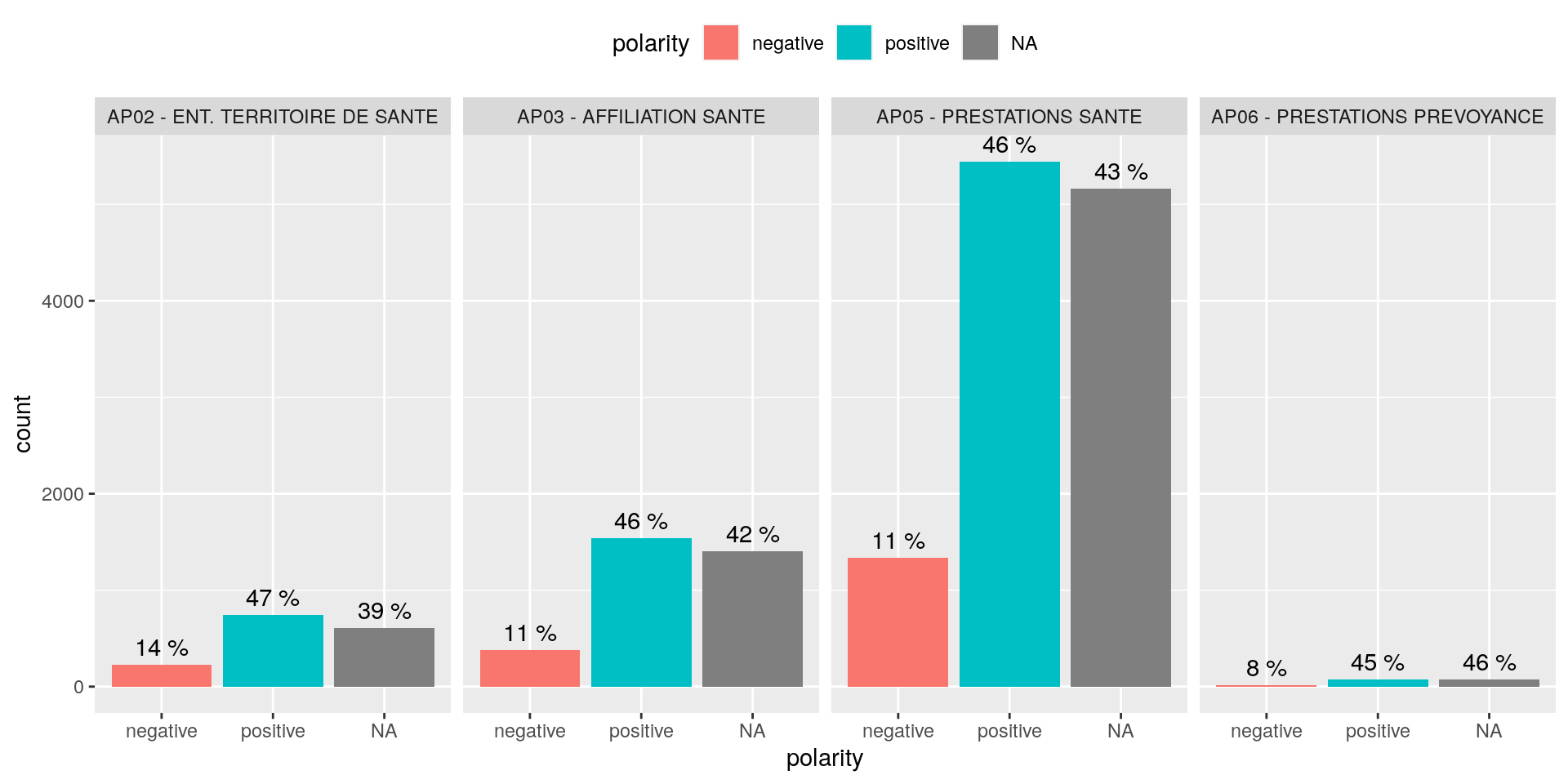
Figure 4.7: Analyse de sentiment !
# plot 2
ggplot(dataPlot[DOMAINE %in% unique(dataPlot$DOMAINE)[5:8],],
aes(x = polarity,
fill = polarity)) +
geom_bar()+
geom_text(aes(label = paste(round((..count..)/ sapply(PANEL, FUN=function(x) sum(count[PANEL == x])) * 100), "%")), stat= "count", vjust = -.5) +
facet_grid(.~DOMAINE)+
theme(legend.position = "top")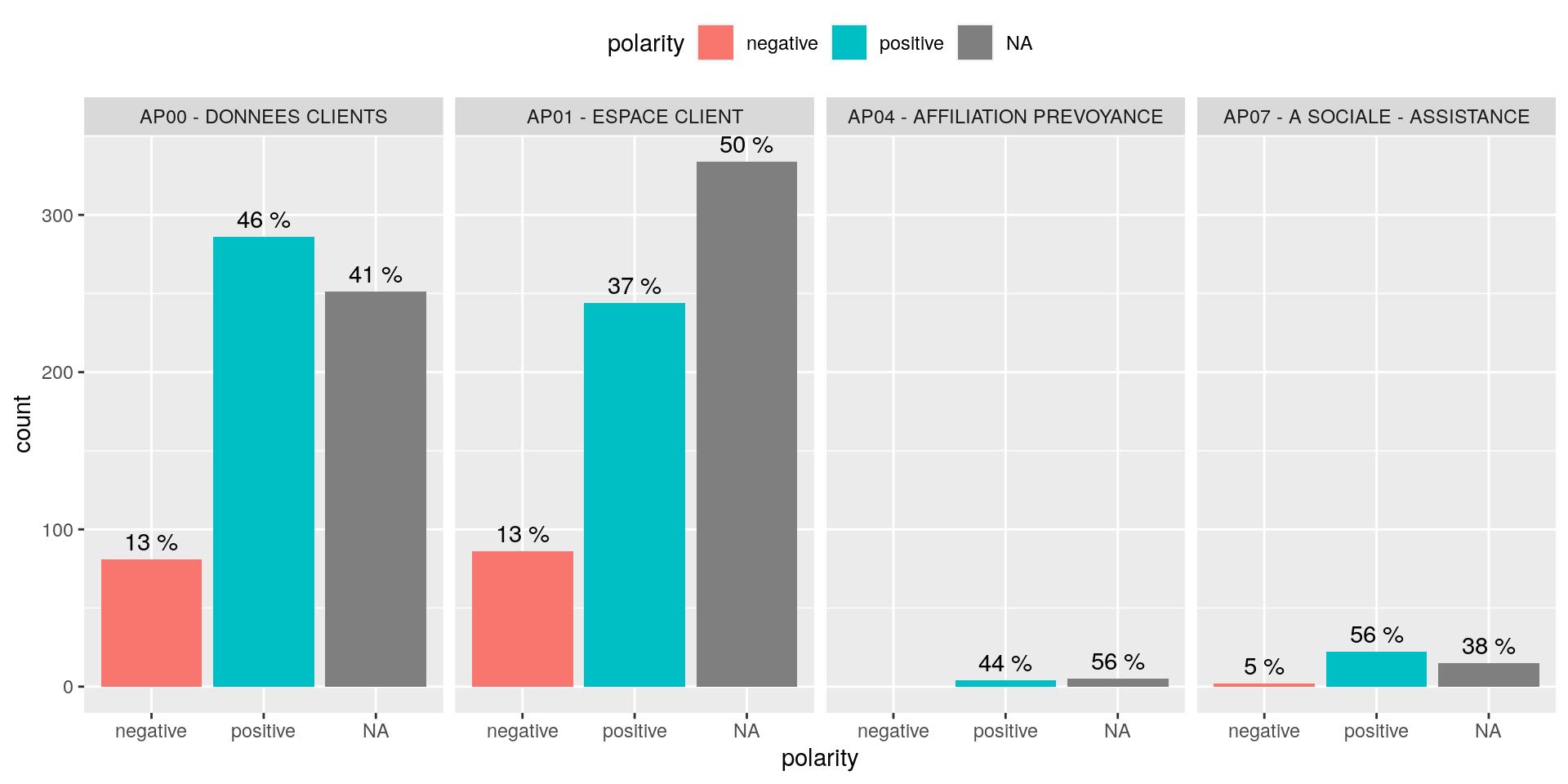
Figure 4.8: Analyse de sentiment !
4.2.8 Cloud Words
Faisons un nuage de mots !
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=1, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=1)
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=1)
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = dataset1NVtidy[,.(n=.N),by=trad][order(-n),.SD[1:20]]
dataPlot = setorder(dataPlot, n)
dataPlot$trad = factor(dataPlot$trad, levels = dataPlot$trad)
ggplotted = ggplot(dataPlot,
aes(trad, n)) +
geom_bar(stat="identity")+
xlab(NULL)+
coord_flip()
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
# sur les mots
dataPlot = dataset1NVtidy[,.(n=.N),by=trad]
# on fixe la partie aléatoire
set.seed(1234)
# magie !
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(2.5,0.25)*1.4,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport(1)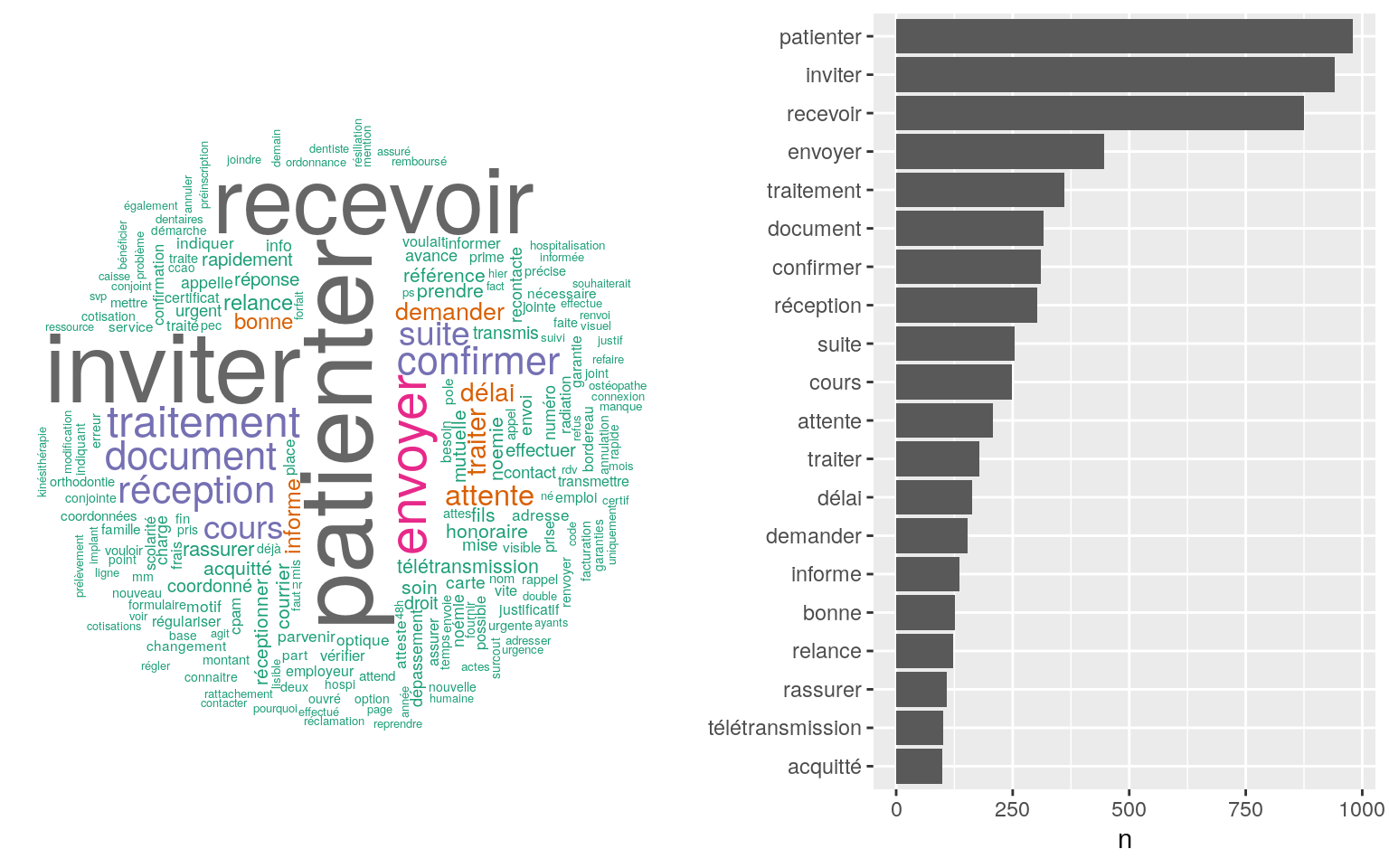
Figure 4.9: Nuage de mot
Faisons un nuage de racine !
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=1, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=1)
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=1)
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = dataset1NVtidy[,.(n=.N),by=stem][order(-n),.SD[1:20]]
dataPlot = setorder(dataPlot, n)
dataPlot$stem = factor(dataPlot$stem, levels = dataPlot$stem)
ggplotted = ggplot(dataPlot,
aes(stem, n)) +
geom_bar(stat="identity")+
xlab(NULL)+
coord_flip()
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
# sur les mots
dataPlot = dataset1NVtidy[,.(n=.N),by=stem]
# on fixe la partie aléatoire
set.seed(1234)
# magie !
wordcloud(words = dataPlot$stem,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(2.5,0.25)*1.5,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport(1)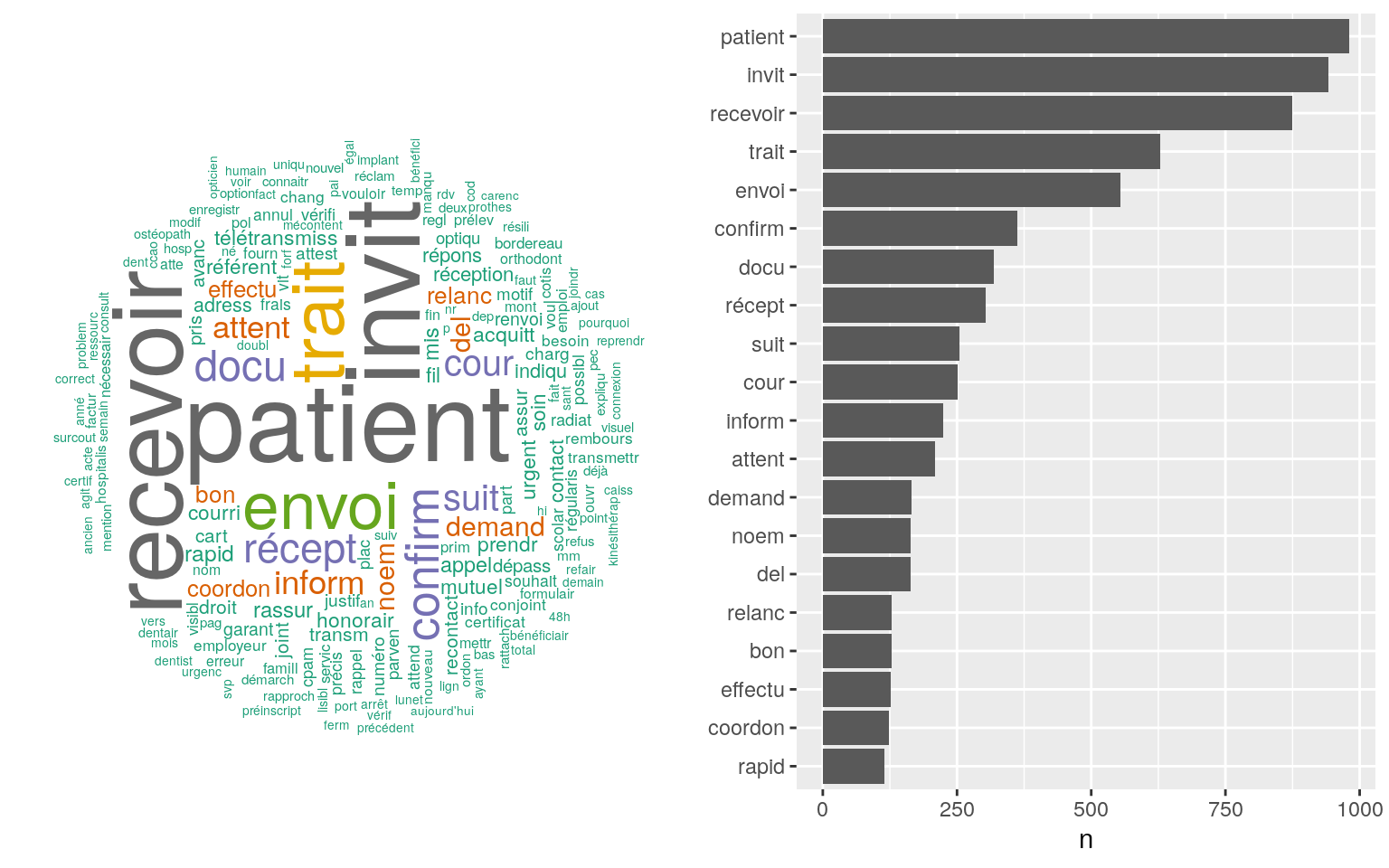
Figure 4.10: Nuage de racine
4.2.9 Association
Il existe deux façon principales d’étudier les associations entre mots :
- la corrélation entre deux mots, c’est à dire à quel point deux mots sont suceptibles de se retrouver dans le même commentaire, par rapport au nombre de fois on l’on peut les retrouver séparément.
- le nombre de fois que deux mots se sont retrouvés dans un commentaire.
(La différence est importante, mais difficle à appréhender !)
Pairs like “Elizabeth” and “Darcy” are the most common co-occurring words, but that’s not particularly meaningful since they’re also the most common individual words. We may instead want to examine correlation among words, which indicates how often they appear together relative to how often they appear separately. : https://www.safaribooksonline.com/library/view/text-mining-with/9781491981641/ch04.html
# calcul du nombre d'occurence par mot et par relance
wordOcur = dataset1NVtidy[,.(n=.N), by = .(trad,relance)]
# matrice des corrélations entre mots
wordCor = as.data.table(pairwise_cor(wordOcur,
trad,
relance,
sort = TRUE))# création igraph
dataPlot = graph_from_data_frame(wordCor[correlation>0.75 &
correlation<0.99,])
# custom
ggraph(dataPlot, layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation),
edge_colour = "royalblue") +
geom_node_point(size = 5) +
geom_node_text(aes(label = name), repel = TRUE,
point.padding = unit(0.2, "lines")) +
theme_void()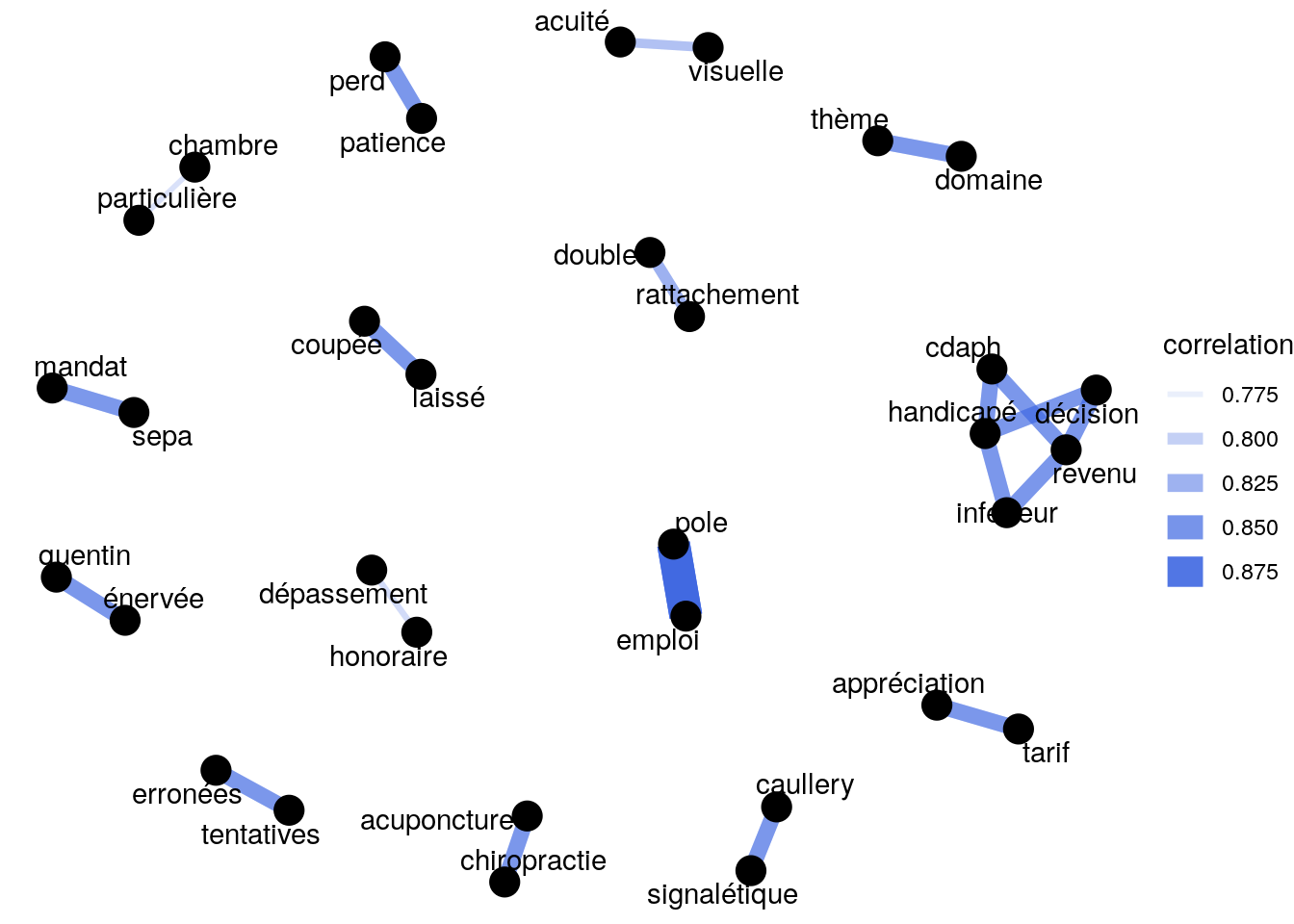
Figure 4.11: Réseau de mot basé sur des corrélations comprises entre 0.75 et 0.99
# matrice des corrélations entre mots
wordCount = as.data.table(pairwise_count(wordOcur,
trad,
relance,
sort = TRUE))# création igraph
dataPlot = graph_from_data_frame(wordCount[n>50,])
# custom
ggraph(dataPlot, layout = "fr") +
geom_edge_link(aes(edge_alpha = n, edge_width = n),
edge_colour = "darkred") +
geom_node_point(size = 5) +
geom_node_text(aes(label = name), repel = TRUE,
point.padding = unit(0.2, "lines")) +
theme_void()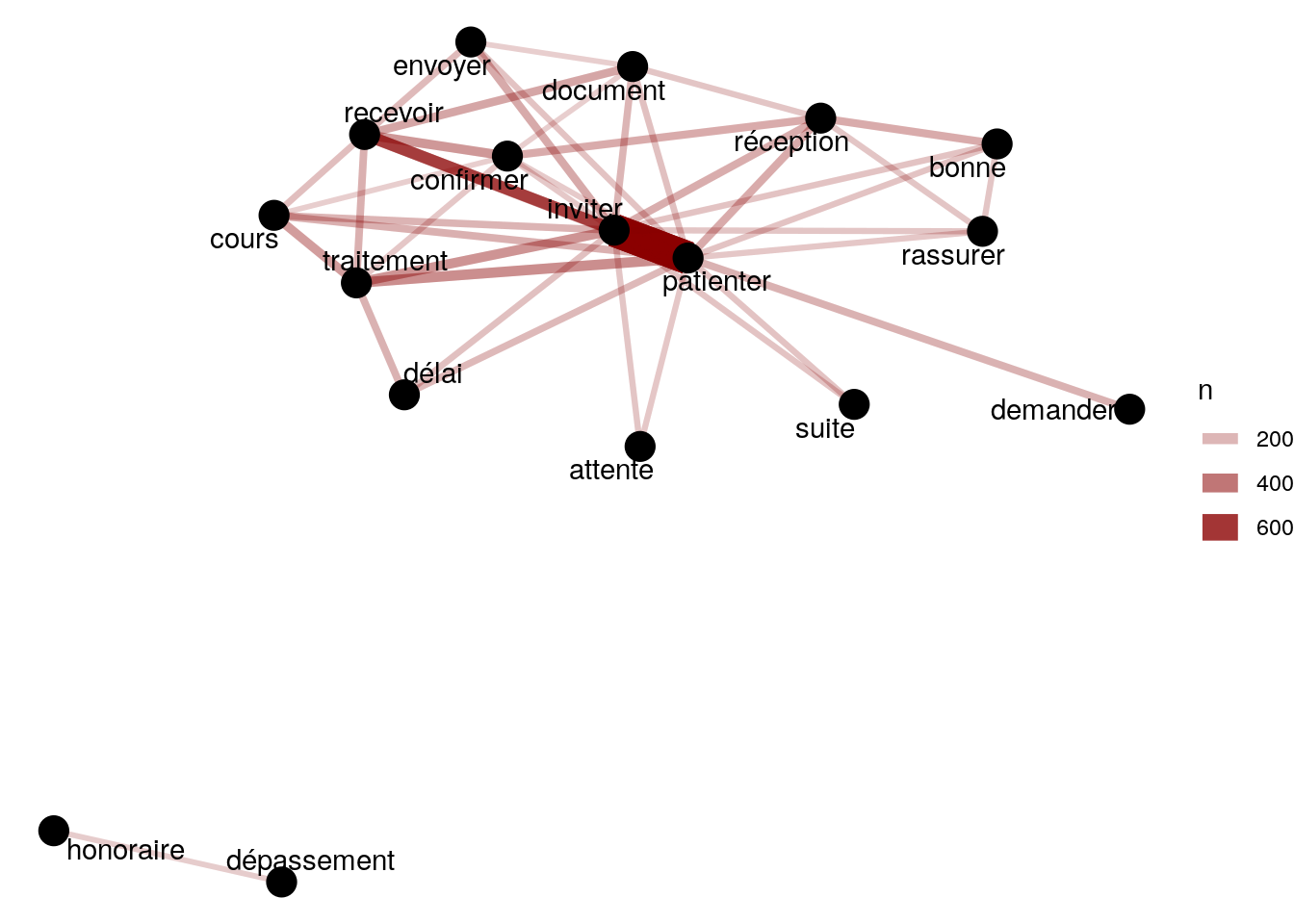
Figure 4.12: Réseau de mot basé sur le nombre de fois que deux mots sont retrouvés dans le même commentaire
4.2.9.1 Comptage sur les 5 mots les plus présents
4.2.9.1.1 “patienter”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[1]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*1,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][n > quantile(n, 0.99),][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()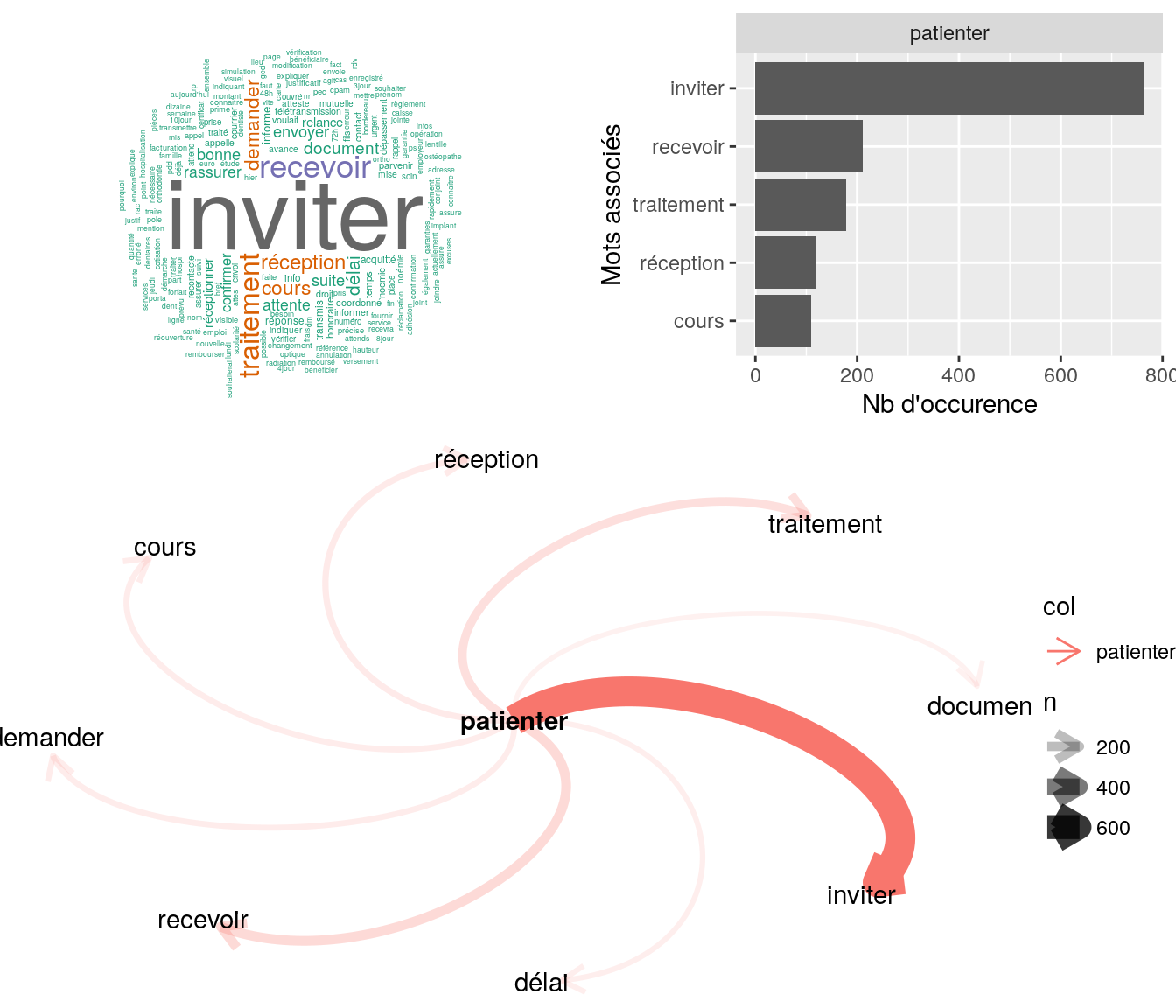
Figure 4.13: Statistiques descriptives liées aux nombres de mots associées au mot ” patienter “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "ai confirmé reception de la facture ostéo, ai invité a patienter pour traitement."
[2] "mme a envoyer attestation ss car le prenom de son fils a une erreur c alexandro et non allexandro demander de patienter"
[3] "mr nous contacte suite problème technique pour ce connecté sur l'espace client = ai indiqué de patienter la remise en service du service client"
[4] "bjr, mme nous recontact ce jour conernant sa demande ai indiquer que nous avons bienr eceptionner le devis. ai inviter a patienter délais de traitement cordialement"
[5] "bjr mme souhaite vérifier bonne réception documents affil- confrime à mme acte naissance + attestation ss ok. invite à patienter cdlt" 4.2.9.1.2 “inviter”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[2]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*1,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][n > quantile(n, 0.99),][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()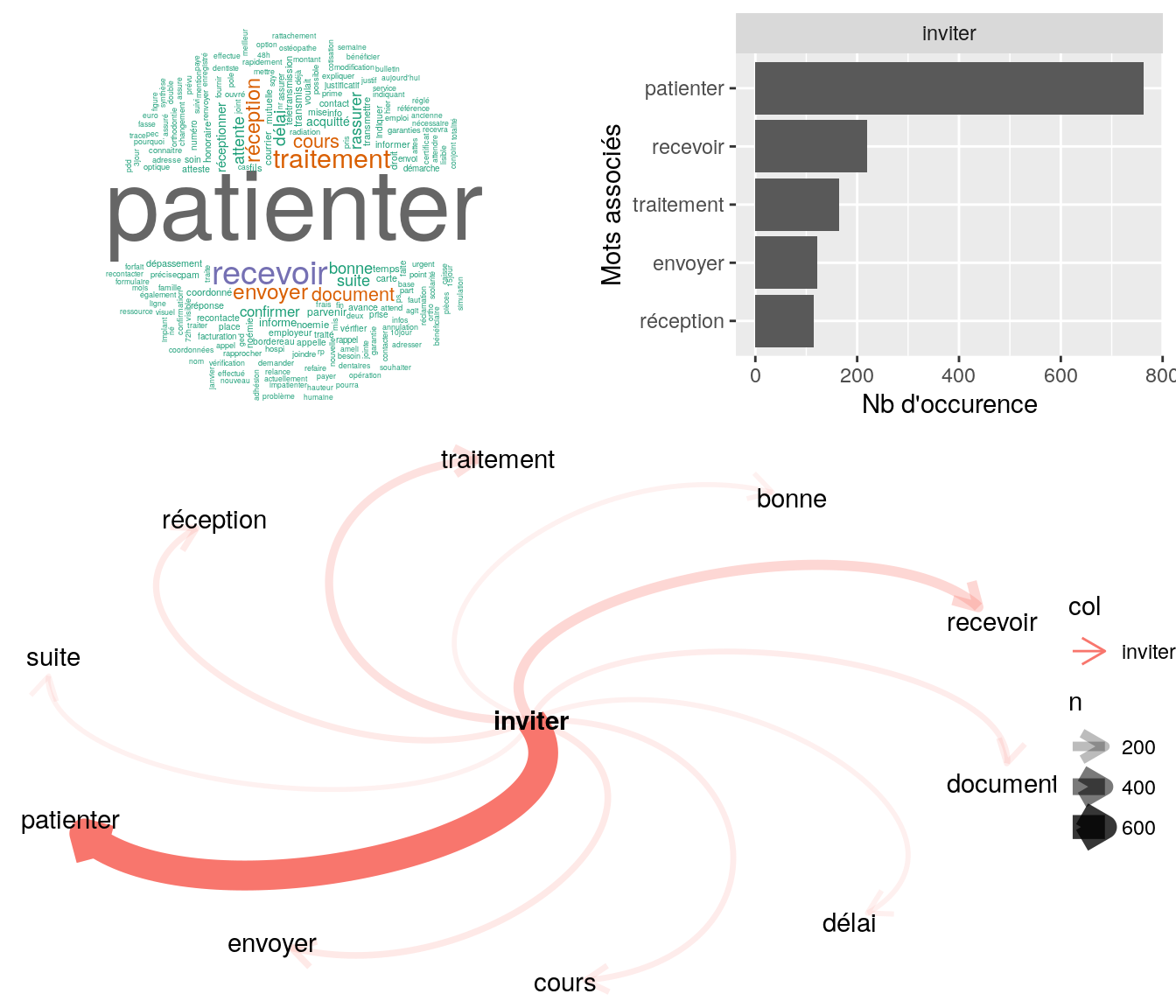
Figure 4.14: Statistiques descriptives liées aux nombres de mots associées au mot ” inviter “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr nous contacte suite a mail recu pour demande de de notification pole emploi mr nous a transmis ce jour inviter a patienter"
[2] "bjr mme demande si son num de ss est a jour j'ai indiquer num pas a jour pour le moment j'ai inviter mme a patienter coord cms ok cdt"
[3] "mr souhaite recevoir attestation de radiation par mail inviter a patienrer"
[4] "bjr mr demande si son devis est traite je l'ai inviter a patienter coorrd cms ok cdt"
[5] "bjr mme demande demande suivi de remb j'ai inviter mme a se rapprocher de la ss pour verifer la base de remb coord cms ok cdt" 4.2.9.1.3 “recevoir”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[3]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.7,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][n > quantile(n, 0.99),][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()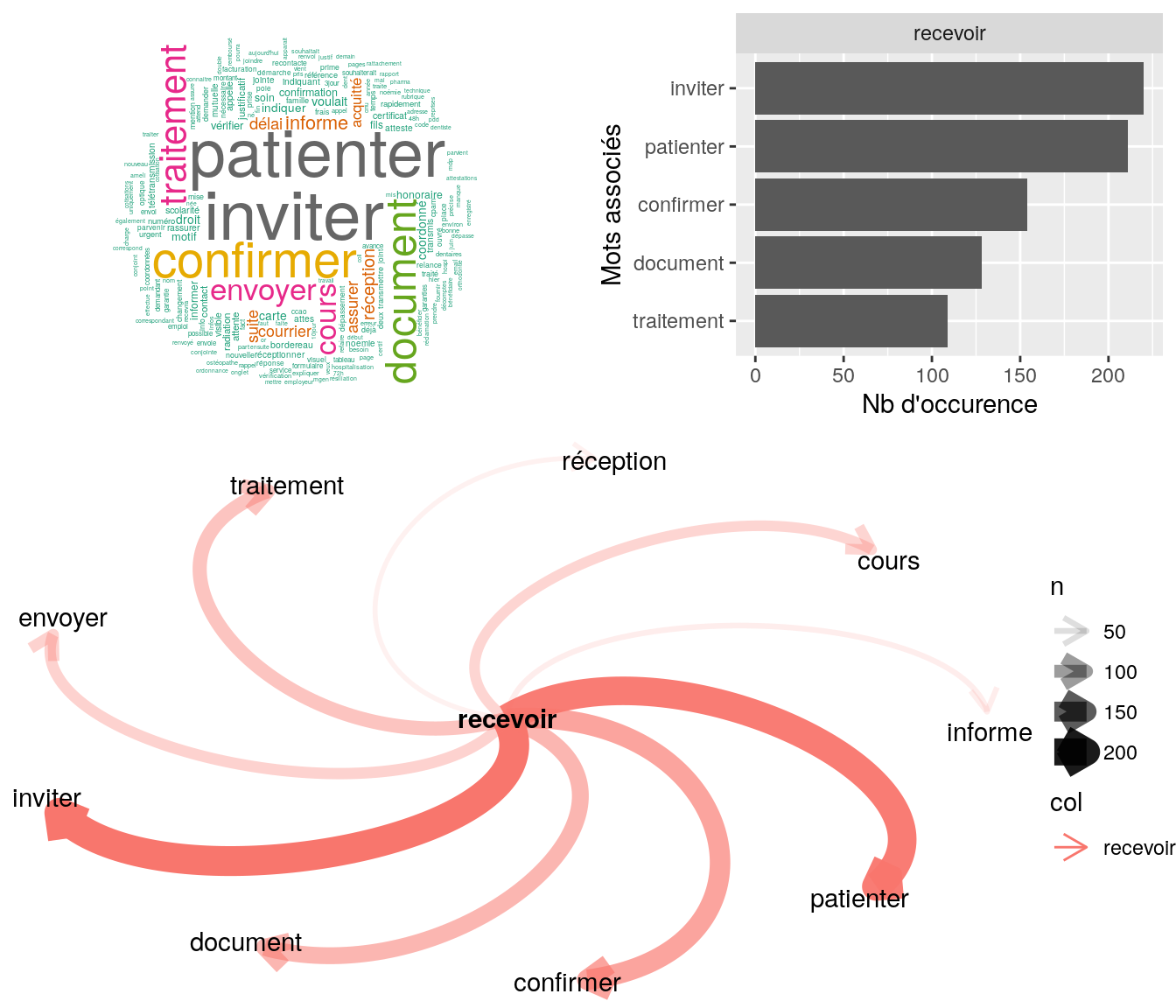
Figure 4.15: Statistiques descriptives liées aux nombres de mots associées au mot ” recevoir “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr ne parvient pas a recevoir nouveau mot de passe ai effectue revisite"
[2] "bjr mr nouqs recontact ce jour car indique ne toujours pas avoir recu decompte mr souhaite decompte papier depuis le 10/10/2016 mr souhaite les recevoir rapidement mr souhaite etre recontacter sur son telephone tel cms ok pour indiquer decompte bien e"
[3] "demander de patienter souhaite la recevoir par mail"
[4] "monsieur veut recevoir une attestation d'affiliation à caractère obligatoire pour sa concubine madame goze emilie. monsieur veut la recevoir par email à gael@roualland.net"
[5] "madame nous contacte pour avoir explications sur mail qu'elle vient de recevoir rassure assurée, indique que les dépassements de 780¤ seraient bien rbsés 2017178mv04asdec00000071 enregistré ce jour en revanche : vous avez pratiqué le tiers-payant con"4.2.9.1.4 “envoyer”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[4]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.7,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][n > quantile(n, 0.99),][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()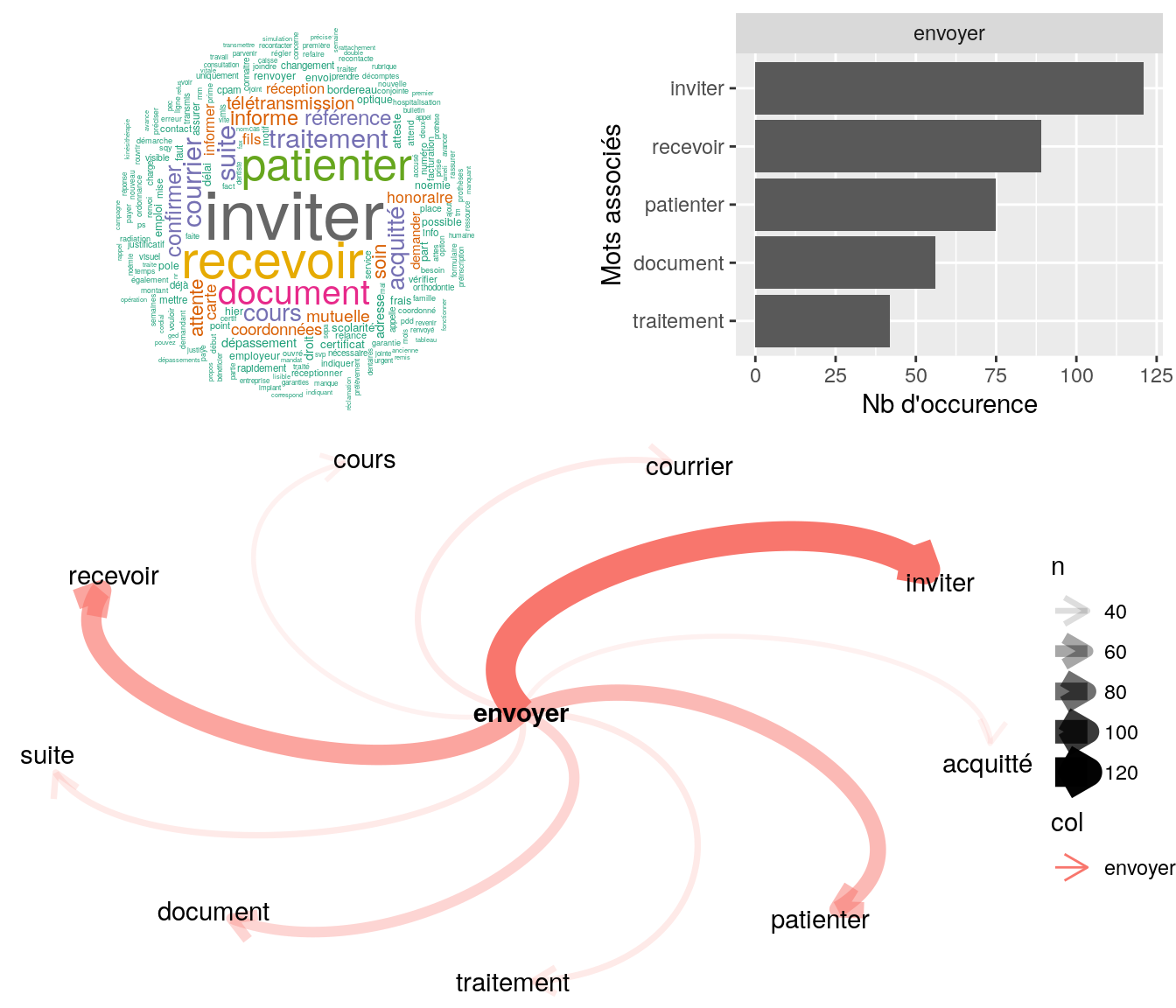
Figure 4.16: Statistiques descriptives liées aux nombres de mots associées au mot ” envoyer “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "motif : attestation affiliation bjr, mme nous demande une attestation d'affiliation avec le caratère \"\"mutuelle familiale\"\" pour l'od et les ad. merci de bien vouloir lui envoyer par mail. coordonnées ok. cdlt"
[2] "bjr, mme nous contacte pour nous avertir que le decompte de ss envoyer correspond a ses frais dentaire pour la facture envoyer par toutm le 27-01-2017 réf : 3584000 merci de faire le remboursement cdlt"
[3] "mme ns a envoyer l'attestation de ss pour maj de la caisse et maj de la teletransmission"
[4] "bjr merci de faire necessaire et envoyer par mail dauphin83110@hotmail.com car mme malentendante cdlt"
[5] "bjr merci d envoyer att ccao cdlt" 4.2.9.1.5 “traitement”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[5]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.9,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][n > quantile(n, 0.99),][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()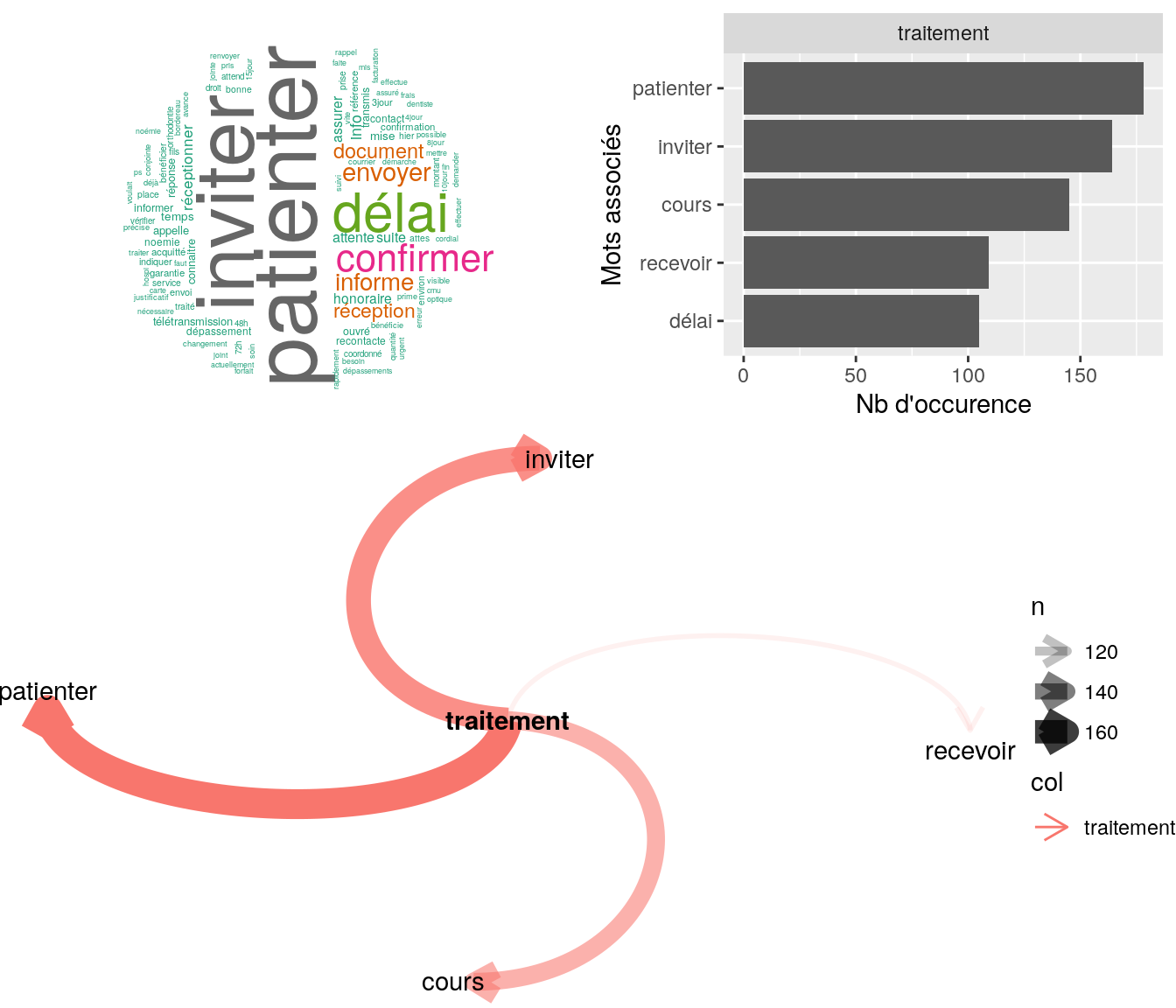
Figure 4.17: Statistiques descriptives liées aux nombres de mots associées au mot ” traitement “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "bien recu les 2 devis, invite à patienter pour le traitement"
[2] "mr ns contacte souhaite savoir si demande prise en compte ai indiquer delais de traitement l'ai inviter a patienetr"
[3] "bjr mr souhaite savoir ou en est l'étude de son devis l'ai invité à patienter, la demande est en cour de traitement cdlt"
[4] "bjr mme nous contacte pour savoir ou en est sa demande d'estimation celle ci est en cour de traitement, l'ai invité à patienter cdlt"
[5] "dossier transmis à géraldine bidault pour rappel de madame qui perd patience dans le traitement de la mise à jour des droits portabilité qui devraient figurer à octobre et non janvier."4.2.9.2 Corrélation sur les 5 mots les plus présents
4.2.9.2.1 “patienter”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[1]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.9,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()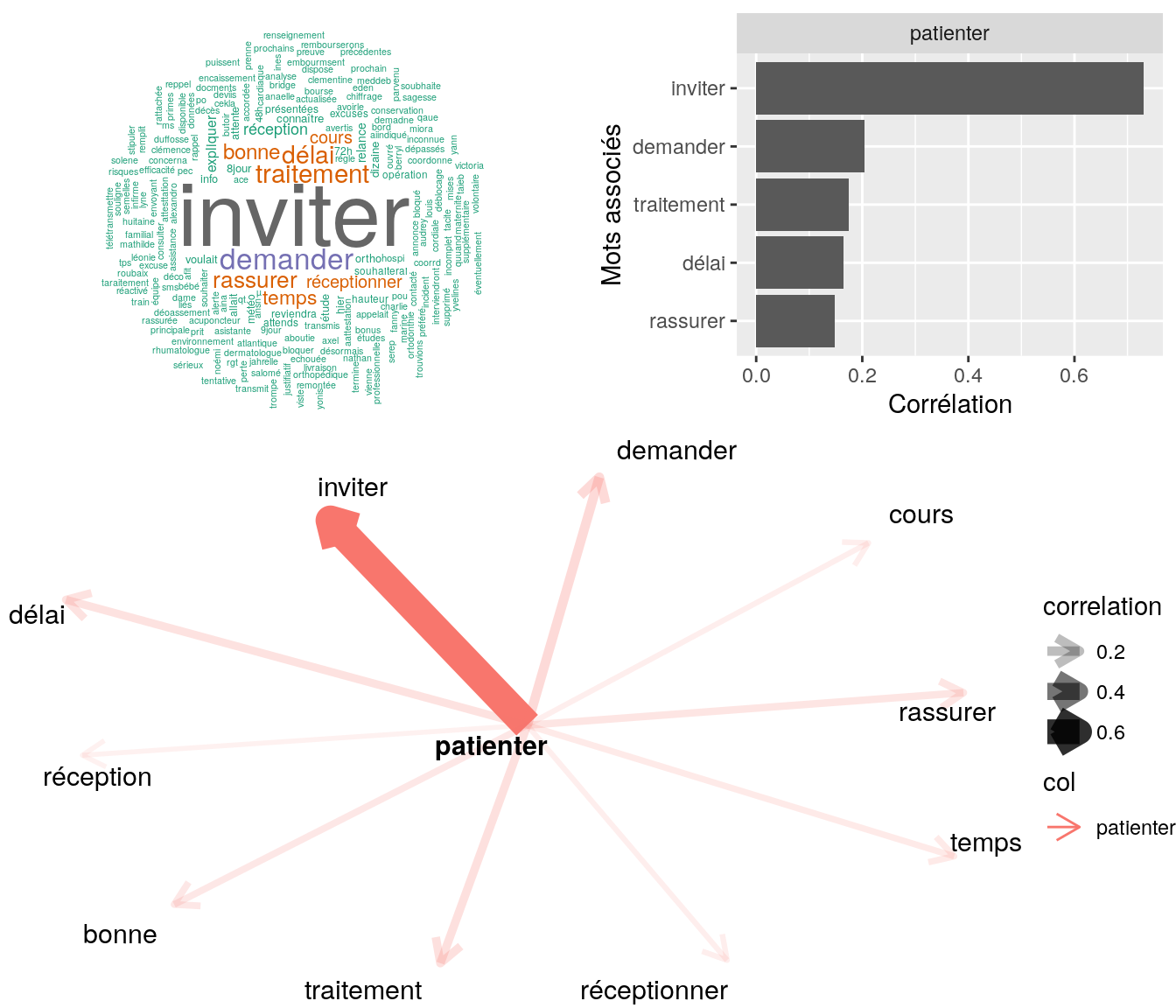
Figure 4.18: Statistiques descriptives liées corrélations associées au mot ” patienter “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mme n'arrive pas a modifier son rib via toutm / il y a un message d'erreur lors de la modification / merci de faire le necessire // invite mme a patienter"
[2] "mr nous contacte pour savoir où en ai l'affiliaition de sa fille l'employeur a transmis tous les documents le 25/01/17 ai invité mr à patienter en cours de traitement"
[3] "bonjour , mr nous rappel pour la meme demande toujours en attente de la mise à jour du centre de ss invite à patienter merci coord cms ok cdt"
[4] "invite mme a patienter demande en cours de traitement"
[5] "bonjour, mr fait suite à sa demande ai indiqué de patienter cdlt" 4.2.9.2.2 “inviter”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[2]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()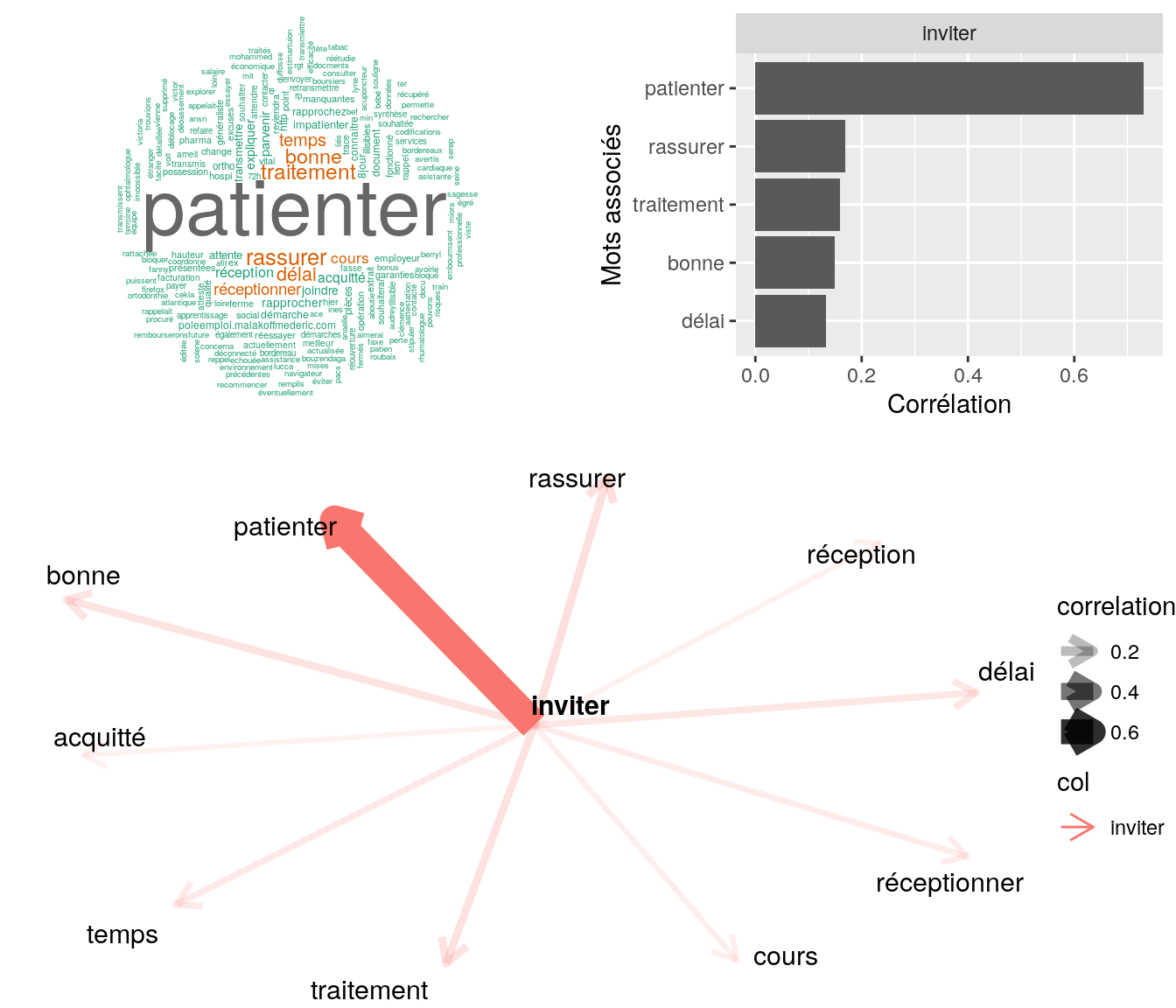
Figure 4.19: Statistiques descriptives liées corrélations associées au mot ” inviter “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr a transmis attestation de ss pour la teletransmission inviter a patienter"
[2] "mr nous contacte pour info sur la teletranslmission nous ajoint attestation de ss pôur mr et les enfants inviter a fire de mleme pour madame inviter a patienter traitement de demande"
[3] "rassure mme sur la bonne reception de attestaiton de droit de son fils afin de faire mise a jour de son n° ss ai inviter a patienté merci cordialement"
[4] "mme nous contact pour s'assurer que nous ayons bien reçu le bordereau de facturation s3404. ai indiquer ok mais illisible on ne voit pas les chiffres. ai inviter mme a refaire un envoie en scannat afin d'abvoir une meilleure visiblité sur les chiffres"
[5] "madame souhaite savoir ce qu'il en ai de son devis ai inviter a patienter" 4.2.9.2.3 “recevoir”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[3]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.5,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()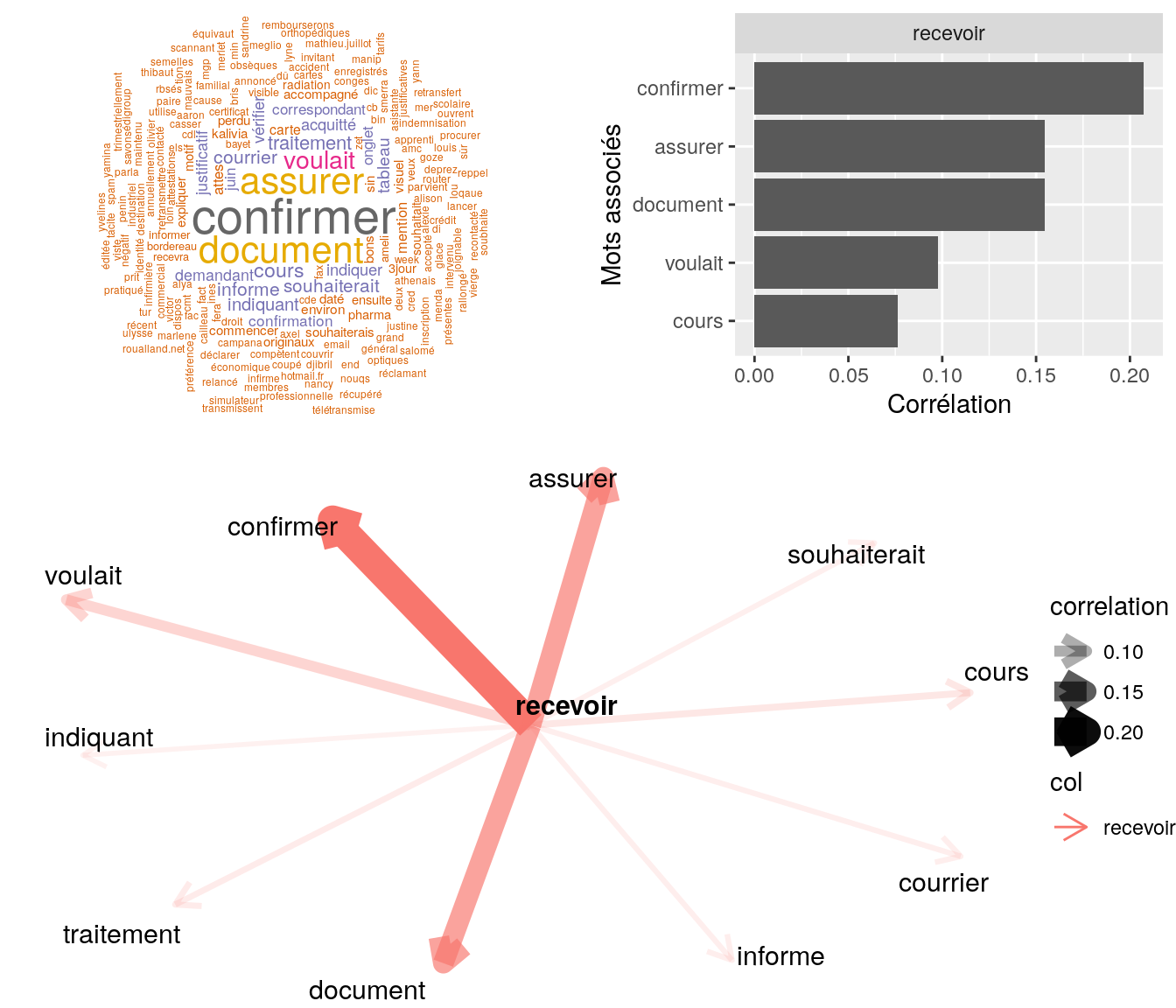
Figure 4.20: Statistiques descriptives liées corrélations associées au mot ” recevoir “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr souhaite suprrimer mme des ayants-droits, courrier visible via ged 20170824_1_cr_aff_019_0013 // invite mr a patienter // mr souahite recevoir par la suite une attestatio de radiaiton par mail / merci de faire le necessaire"
[2] "mr souhaite recevoir par mail une attestation d'affiliation à caractère obligatoire avc la mention \"\"famille\"\" concernant son fils / invite mr a patienter"
[3] "mr souhaite recevoir par mail de preference"
[4] "bjr, mr nous contacte car ne souhaite pas le remboursement des soins en piéces jointes à sa demande toutm mais une attestation de non remboursement pour ceux-ci. il souhaite recevoir le document par mail. ai invité à patienter et à suivre sa demande via"
[5] "mme nous contacte car on lui à indiquée hier 15 min pour recevoir estimation indique à mme min 48h invite à patientée" 4.2.9.2.4 “envoyer”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[4]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.3,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()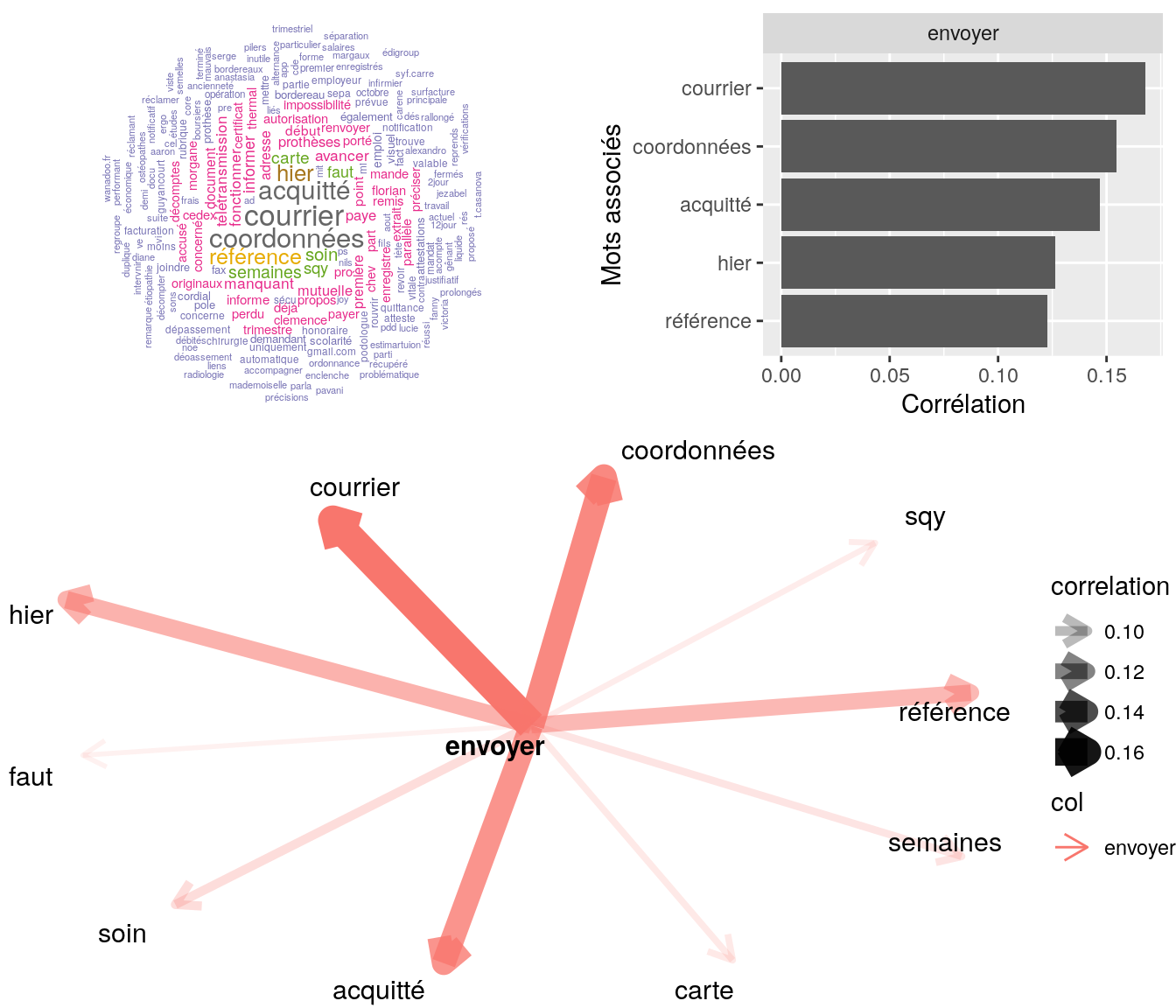
Figure 4.21: Statistiques descriptives liées corrélations associées au mot ” envoyer “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr demande si pj bien recu / confirme a mr avoir bien recu facture dentaire tm / expl inuitle envoyer attes ss /"
[2] "relance invite à envoyer bordereau de facturation en plus cdt"
[3] "bjr, mme nous contacte pour nous avertir que le decompte de ss envoyer correspond a ses frais dentaire pour la facture envoyer par toutm le 27-01-2017 réf : 3584000 merci de faire le remboursement cdlt"
[4] "date : 05/09/2017 mme nous contacte pour double rattachement de enfant a envoyé son attest droits et aui invité à envoyer celle de mr"
[5] "bonjour mme nous a envoyer son decompte puisque la télétransmission n'a pas fonctionner je l'invite à patienter" 4.2.9.2.5 “traitement”
# on choisit le mot
mot = dataset1NVtidy[,.(n=.N),by=trad][order(-n)][,.SD[5]][,trad]
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.7,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()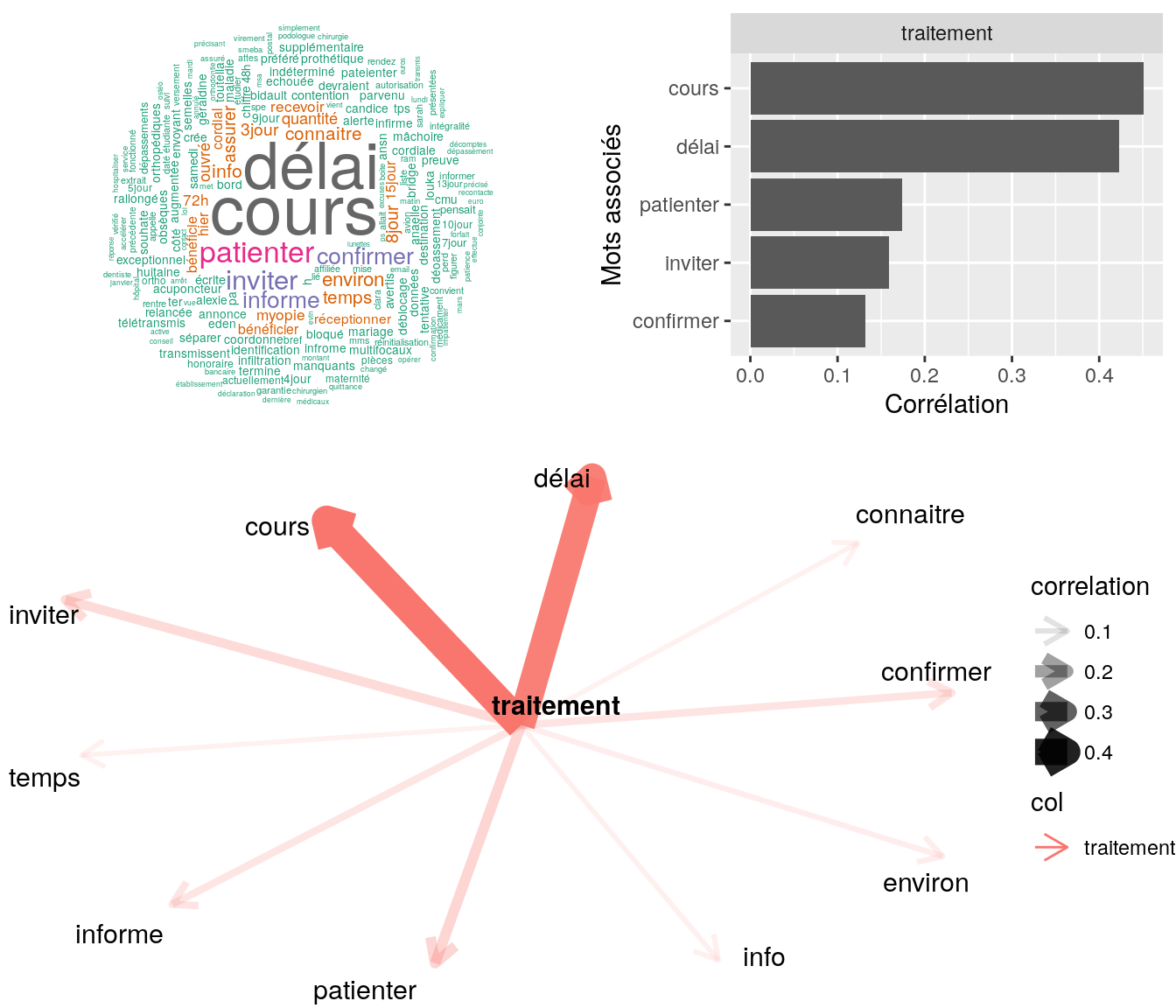
Figure 4.22: Statistiques descriptives liées corrélations associées au mot ” traitement “
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "monsieur souhaite savoir a quel date va etre faite la maj invitez a patientez - traitement dans les plus bref délais"
[2] "mr souhate traitement de la demande cdlt"
[3] "mme ns contacte car n'a pas eu de réponse du devis ai informer traitement en cours et l'invite à patientez"
[4] "bonjour, madame souhaite s'assurer que nous avons reçu sa facture acquittée suite hospi + décompte ss et ses factures acquittées pour séances d'ostéopathe. lui confirme la réception de ces documents et l'informe que la demande est en cours de traitement."
[5] "bonjour, madame souhaite connaitre montant du remboursement pour dépassements d'honoraires en hospitalisation. lui confirme que nous avons bien reçu le devis envoyé ce jour et que la demande est en cours de traitement. merci cordialement" 4.2.10 Cas particulier de certains mots
4.2.10.1 “acquitté”
4.2.10.1.1 Comptage
# on choisit le mot
mot = "acquitté"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()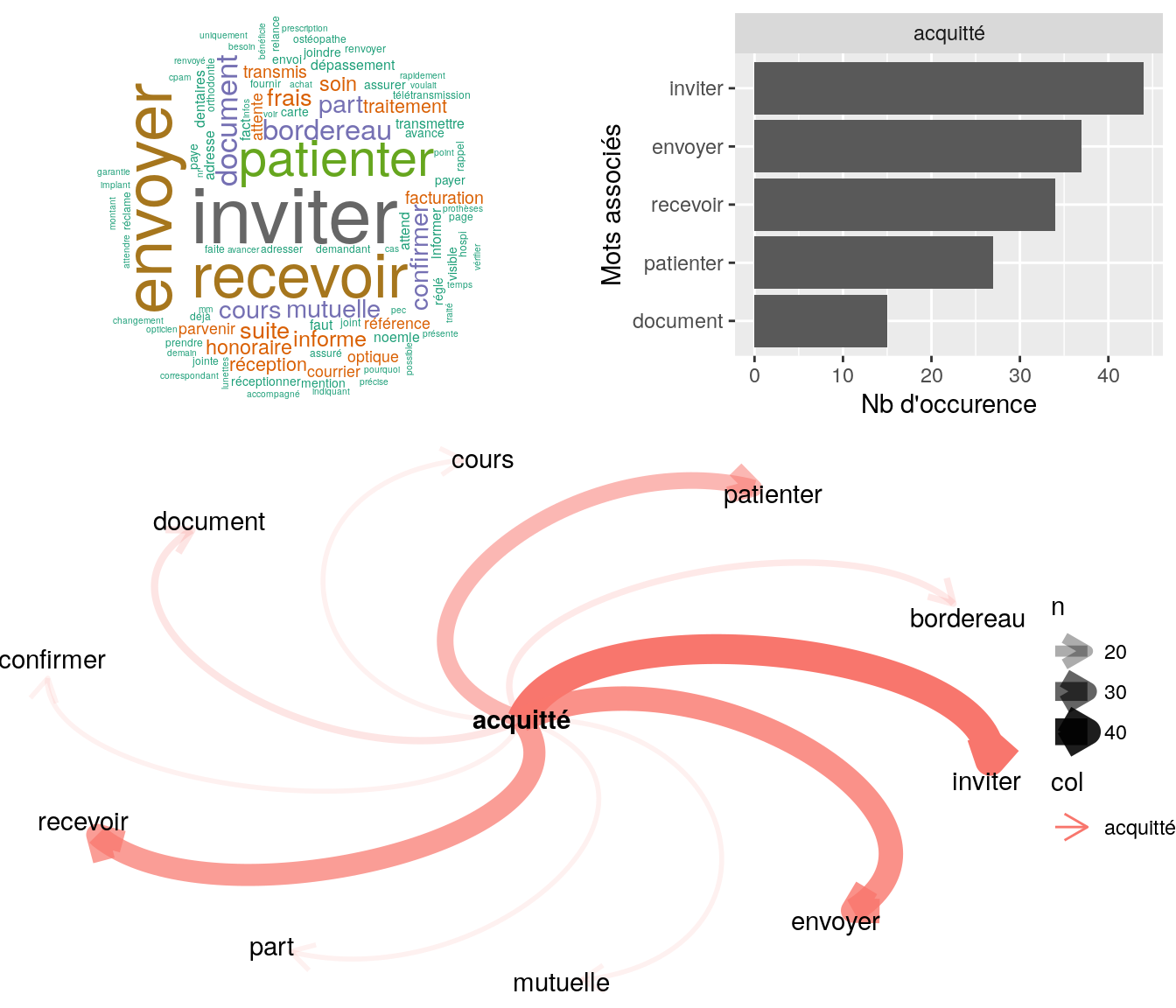
Figure 4.23: Statistiques descriptives liées aux nombres de mots associés à acquitté
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "ai indiqué que noemie est bien en place - ai indique d envoyer attestation cpam + facture acquitté"
[2] "bjr mr souhaite vérifier réception devis lui confirme devis reçu invite à patienter pour retour + pour rbsmt devra envoyer bordereau facturation acquitté par toutm cdlt"
[3] "bonjour mme nous contacte suite remb dentiste mme nous a transmis facture acquitté le 30.05.17 sur toutm ref 3937252. invite a patienter merci d'avance cdlt"
[4] "bjr ai indiqué à mme qu'il nous faut aussi le facture acquitté l'ai invitée à nousl'envoyer en relance de ce formulaire toutm cdt"
[5] "bjr, mme mécontente, nous relance suite mail reçu demandant bordereau s3404 acquitté. document joint est déjà s3404 acquitté. infos sur montant total + part amc (brss) + part amc + part assuré visibles sur le document et la notion d'acquittement y est in"4.2.10.1.2 Corrélation
# on choisit le mot
mot = "acquitté"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.3,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()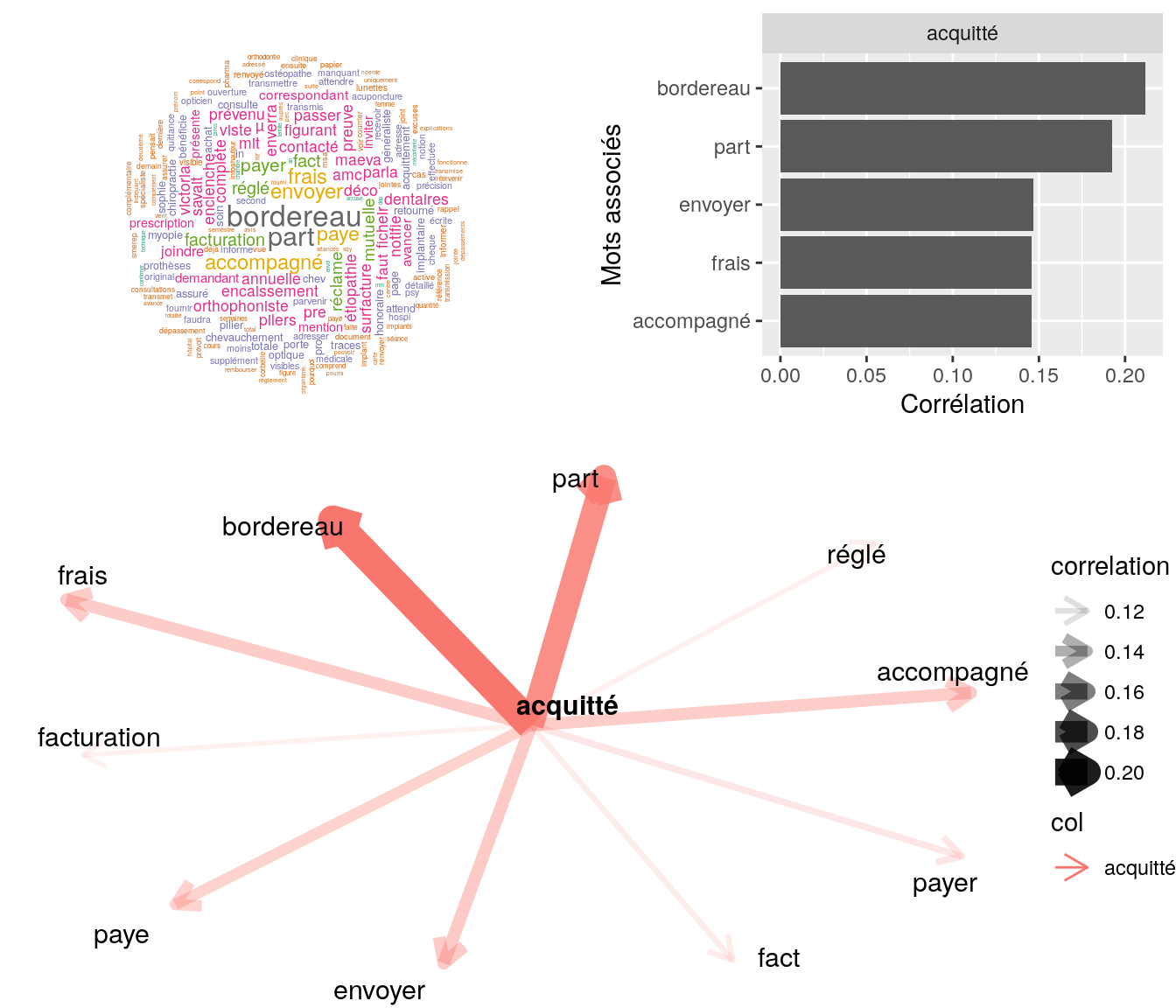
Figure 4.24: Statistiques descriptives liées corrélations associées à “acquitté”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr m'informe qu'il a renvoyé la facture acquitté pour etre remboursé des 17¤ car il a reçu un courrier de mm indiquant qu'ils ne savait pas a quoi correspondant le code sur la facture // mr a renvoyé la facture avec la précision faite par la clinqiue// j"
[2] "ai indiqué que noemie est bien en place - ai indique d envoyer attestation cpam + facture acquitté"
[3] "bjr mr souhaite vérifier réception devis lui confirme devis reçu invite à patienter pour retour + pour rbsmt devra envoyer bordereau facturation acquitté par toutm cdlt"
[4] "bjr ai indiqué à mme qu'il nous faut aussi le facture acquitté l'ai invitée à nousl'envoyer en relance de ce formulaire toutm cdt"
[5] "bjr, mme mécontente, nous relance suite mail reçu demandant bordereau s3404 acquitté. document joint est déjà s3404 acquitté. infos sur montant total + part amc (brss) + part amc + part assuré visibles sur le document et la notion d'acquittement y est in"4.2.10.2 “délai”
4.2.10.2.1 Comptage
# on choisit le mot
mot = "délai"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*1.1,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()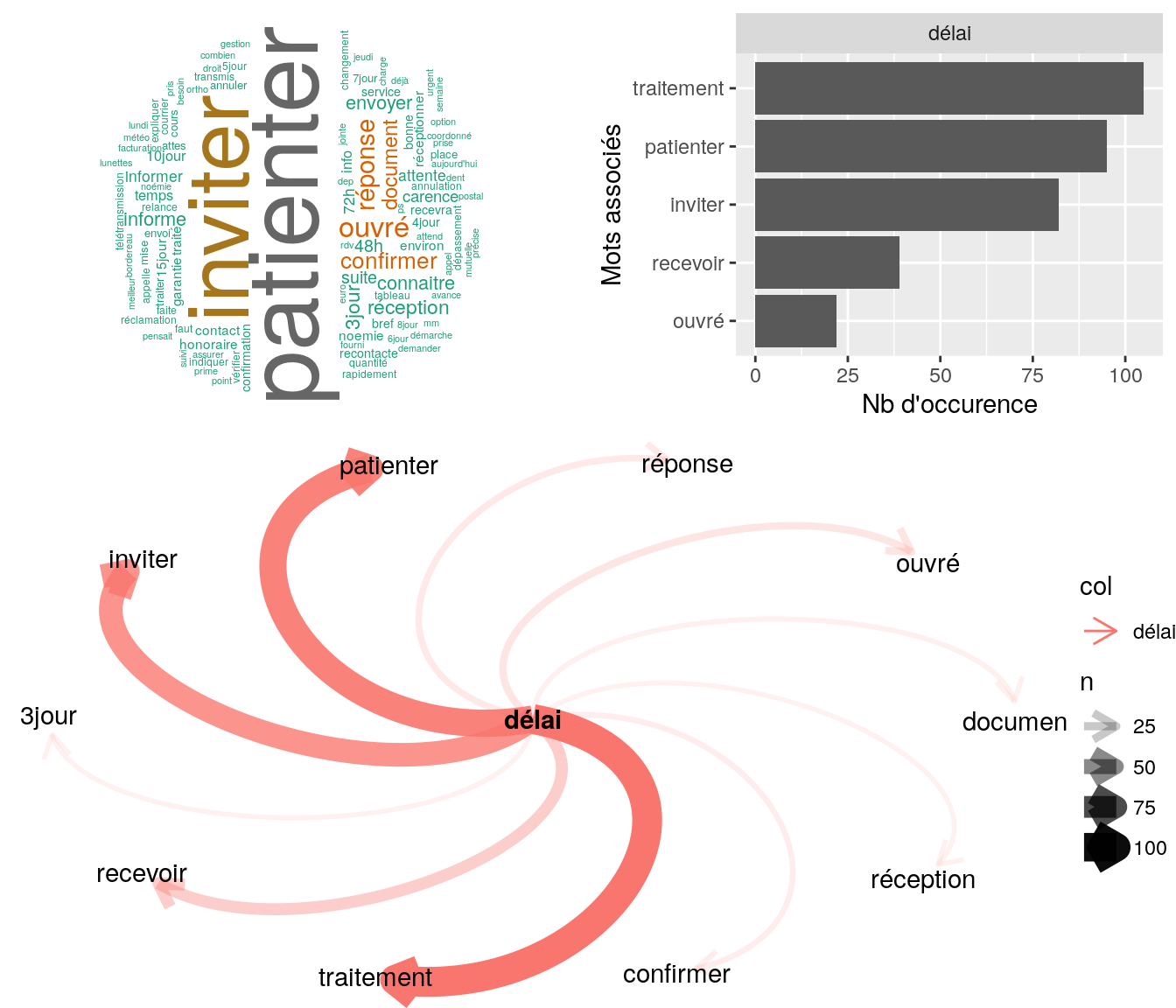
Figure 4.25: Statistiques descriptives liées aux nombres de mots associés à délais
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "bonjour, fille de mr souhaite connaitre estimation remboursement suite devis dentaire envoyé le 19/11/17 par toutm. l'informe que la demande est en cours de traitement, délai de traitement 48h. merci cordialement"
[2] "mrs aimerais savoir ou en est sa demande de remboursment pour podologue il avait déja envoyé via toutm il y a quelques jours ai indiqué que ce jour la demande est bien enregistré ai indiqué de patienté quelques jours délai de traitement"
[3] "bjr mr souhaite savoir si nous avons bien recu sa demande d'annualtion : ok l'informe que cause délai sa demande sera bientot traité par la service de gestion, mr recevra retour par mail ou courrier postal cdt"
[4] ".mr veut connaitre réponse devis indique à mr délai 48h pour traiter le devis 817.25¤ par oeuil"
[5] "monsieur nous contacte pour savoir où en est sa demande d'annulation du délai de carence. l'ai invité à patienter. monsieur demande une réponse par mail." 4.2.10.2.2 Corrélation
# on choisit le mot
mot = "délai"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.6,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()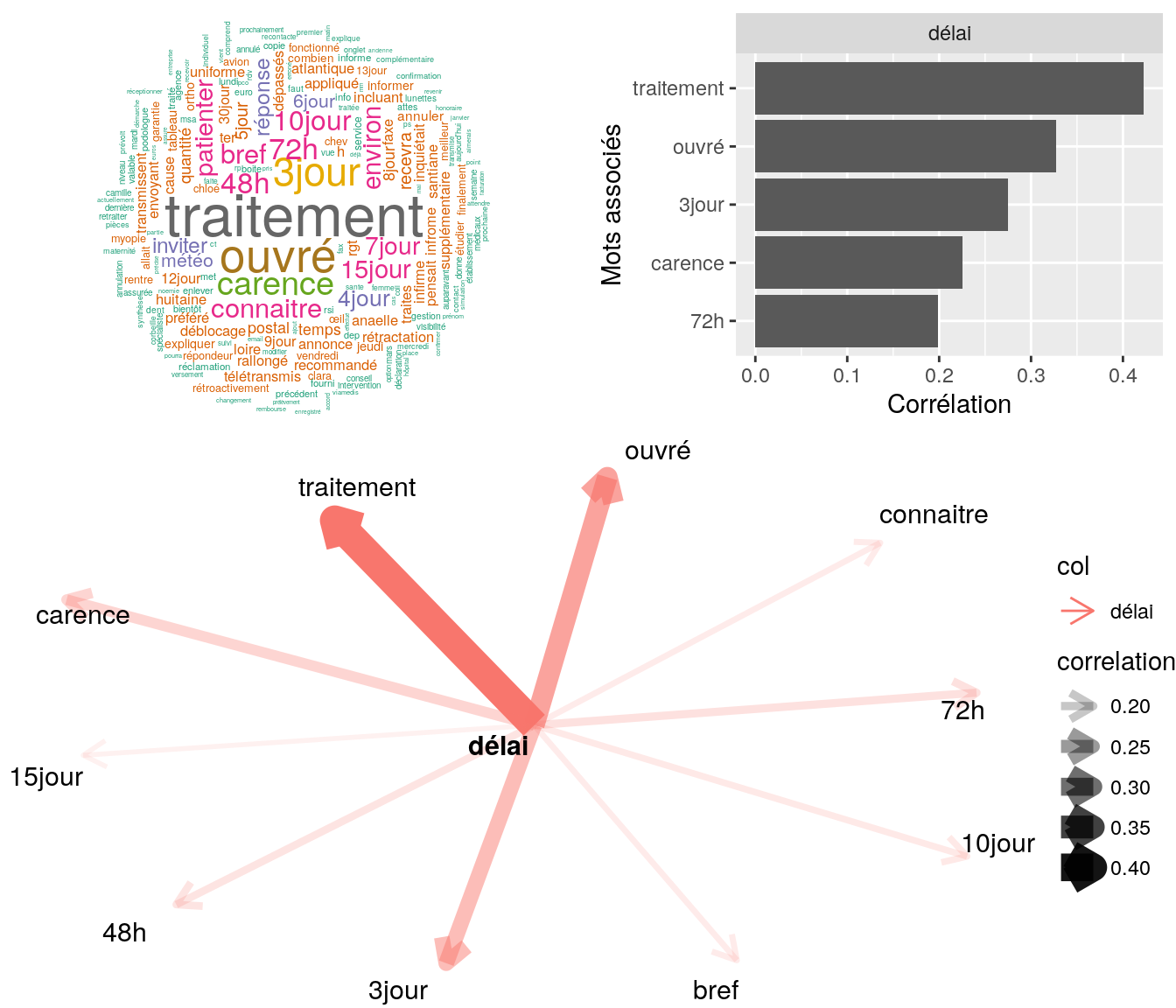
Figure 4.26: Statistiques descriptives liées corrélations associées à “délais”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr souhaite savoir si on a bien reçu ls docs indique à mme que oui délai traitement attendre"
[2] "mr nous contacte pour connaitre le délai pour l'envoi de l'estimation du devis. ai indiqué 3jour."
[3] "bjr mr souhaite savoir si bien recu devis: oui + souhaite connaitre délai de traitement : 4jour a ce jour cdt"
[4] "bonjour, madame souhaite s'assurer que la réclamation qu'elle a fait ce jour sur toutm a bien été réceptionné et sous quel délai elle va être traitée. lui confirme la réception de sa demande et l'informe que ce sera traité dans les plus brefs délais. me"
[5] "bonjour, madame nous contacte pour savoir si le délai de carence a été annulé suite à l'envoi du tableau des garanties de son ancienne mutuelle. l'informe que c'est en cours de traitement, l'invite à patienter. merci cordialement" 4.2.10.3 “réceptionner”
4.2.10.3.1 Comptage
# on choisit le mot
mot = "réceptionner"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*1.1,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()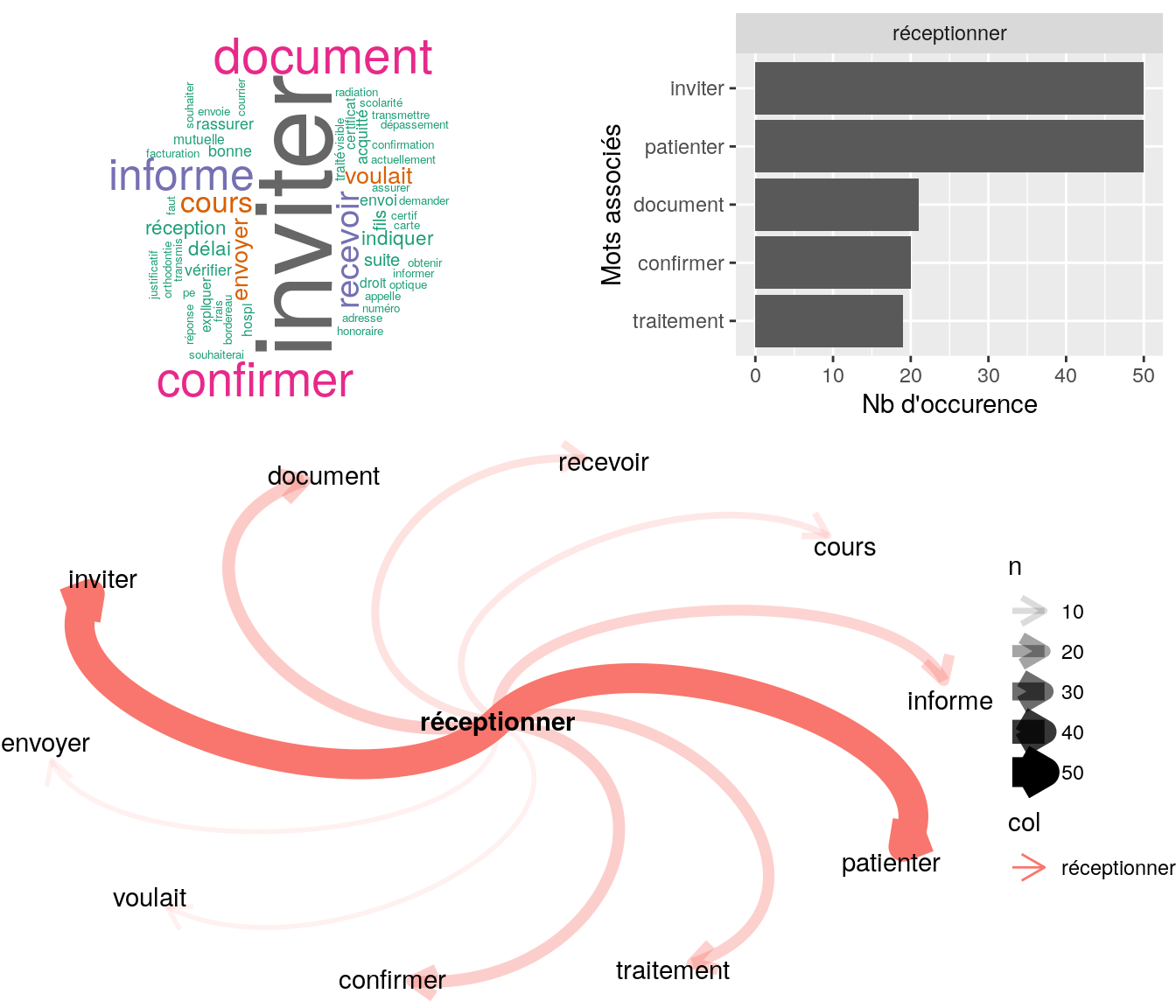
Figure 4.27: Statistiques descriptives liées aux nombres de mots associés au mot “réceptionner”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "bjr mr souhaite savoir si on a bien réceptionner l'attestation de droit ss envoyer via toutm le 04/01 réf : 3512283 informe le client qu'on la bien réceptionner l'attestation es en cours de traitement merci cdlt"
[2] "bjr mme souhaite s'assuré qu'on a bien receptionner la facture acquitter concernant des frais d'orthodontie nr je confirme a la cliente que la facture acquitter a bien etait réceptionner celle ci est en cours de traitement invite a suivre le traitemen"4.2.10.3.2 Corrélation
# on choisit le mot
mot = "réceptionner"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.4,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()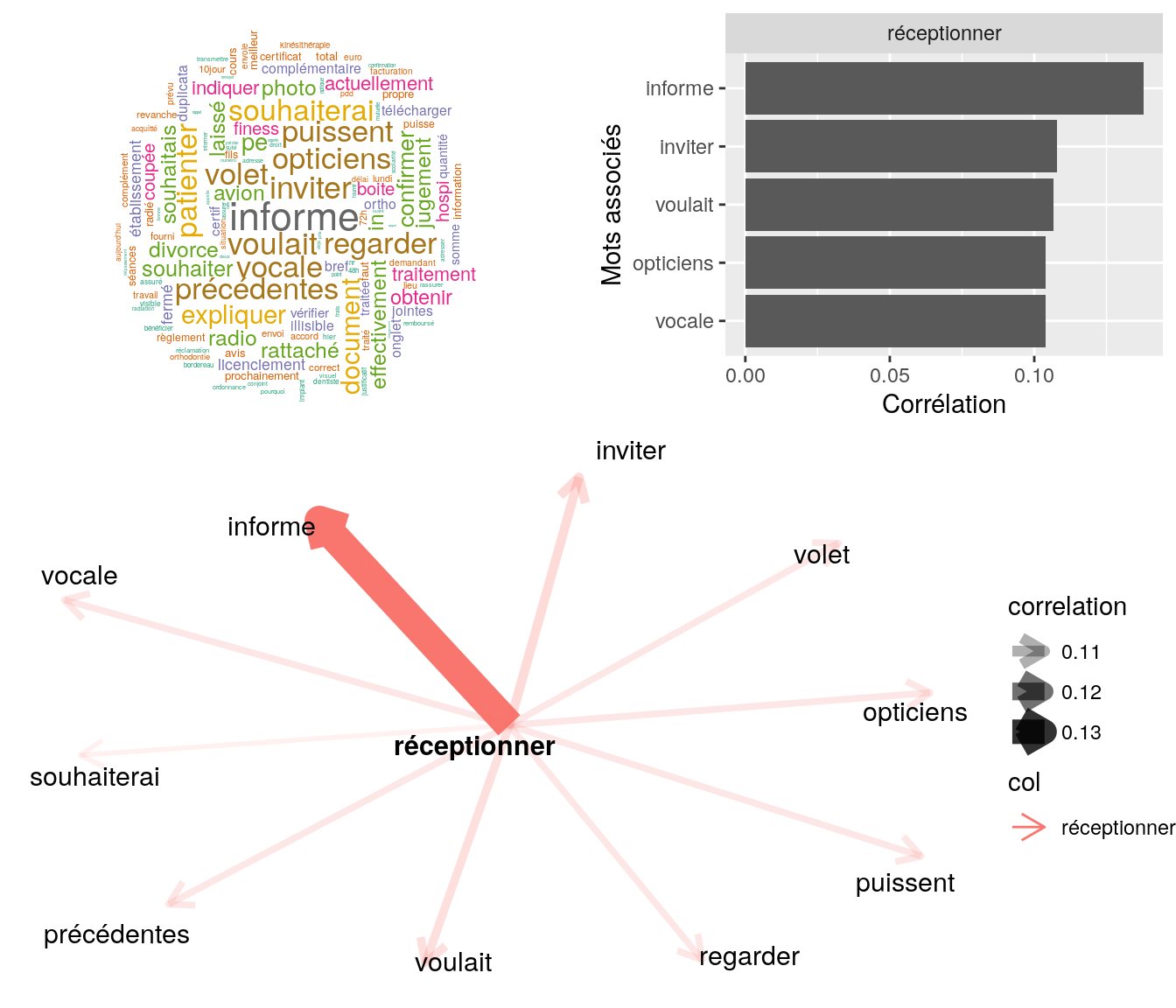
Figure 4.28: Statistiques descriptives liées corrélations associées au mot “réceptionner”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "bjr mr souhaite savoir si on a bien réceptionner l'attestation de droit ss envoyer via toutm le 04/01 réf : 3512283 informe le client qu'on la bien réceptionner l'attestation es en cours de traitement merci cdlt"
[2] "bjr mme souhaite s'assuré qu'on a bien receptionner la facture acquitter concernant des frais d'orthodontie nr je confirme a la cliente que la facture acquitter a bien etait réceptionner celle ci est en cours de traitement invite a suivre le traitemen"4.2.10.4 “rassurer”
4.2.10.4.1 Comptage
# on choisit le mot
mot = "rassurer"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()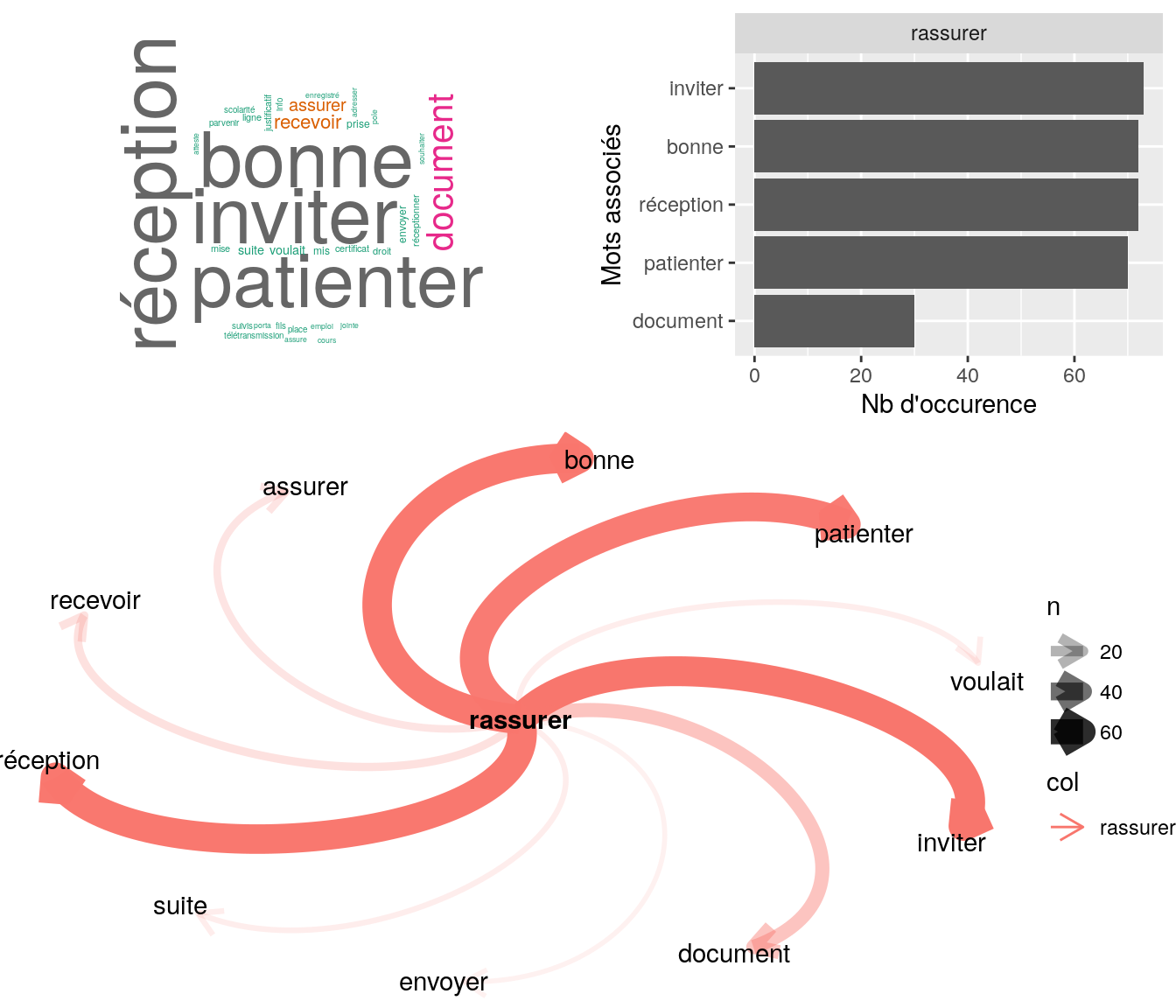
Figure 4.29: Statistiques descriptives liées aux nombres de mots associés au mot “rassurer”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "ai rassurer sur la bonne reception des justifiactifs"
[2] "mme voulait savoir si nous avons bien receptionne ses documents ai rassurer sur la bonne reception invite a patienter"
[3] "ai rassurer sur la bonne reception des documents invite a patienter"
[4] "ai rassurer mme sur la bonne reception de ses justificatifs invite mme a patienter"
[5] "ai rassurer sur la bonne reception des documents invite a patienter" 4.2.10.4.2 Corrélation
# on choisit le mot
mot = "rassurer"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()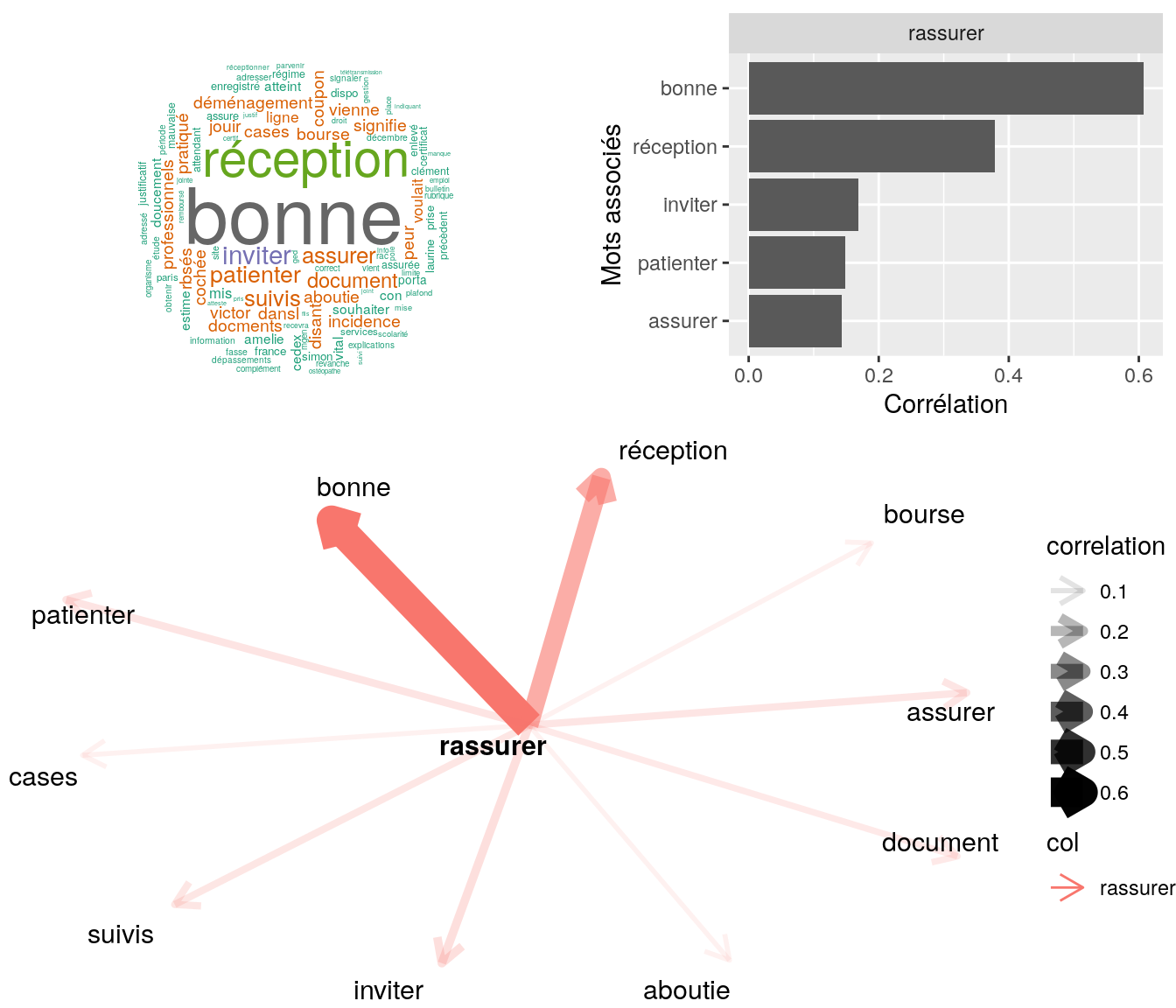
Figure 4.30: Statistiques descriptives liées corrélations associées au mot “rassurer”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "ai rassurer sur la bonne reception du certificat de scolarite invite a patienter"
[2] "ai rassurer sur la bonne reception de ses documents invite a patienter"
[3] "ai rassurer mme sur le fait de la bonne reception de son document invite a patienter"
[4] "ai rassurer mme que nous avons bien reception ses justificatifs . invite mme a patienter"
[5] "ai rassurer mme sur la bonne reception de ses documents invite mme a patienter" 4.2.10.5 “expliquer”
4.2.10.5.1 Comptage
# on choisit le mot
mot = "expliquer"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:5]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()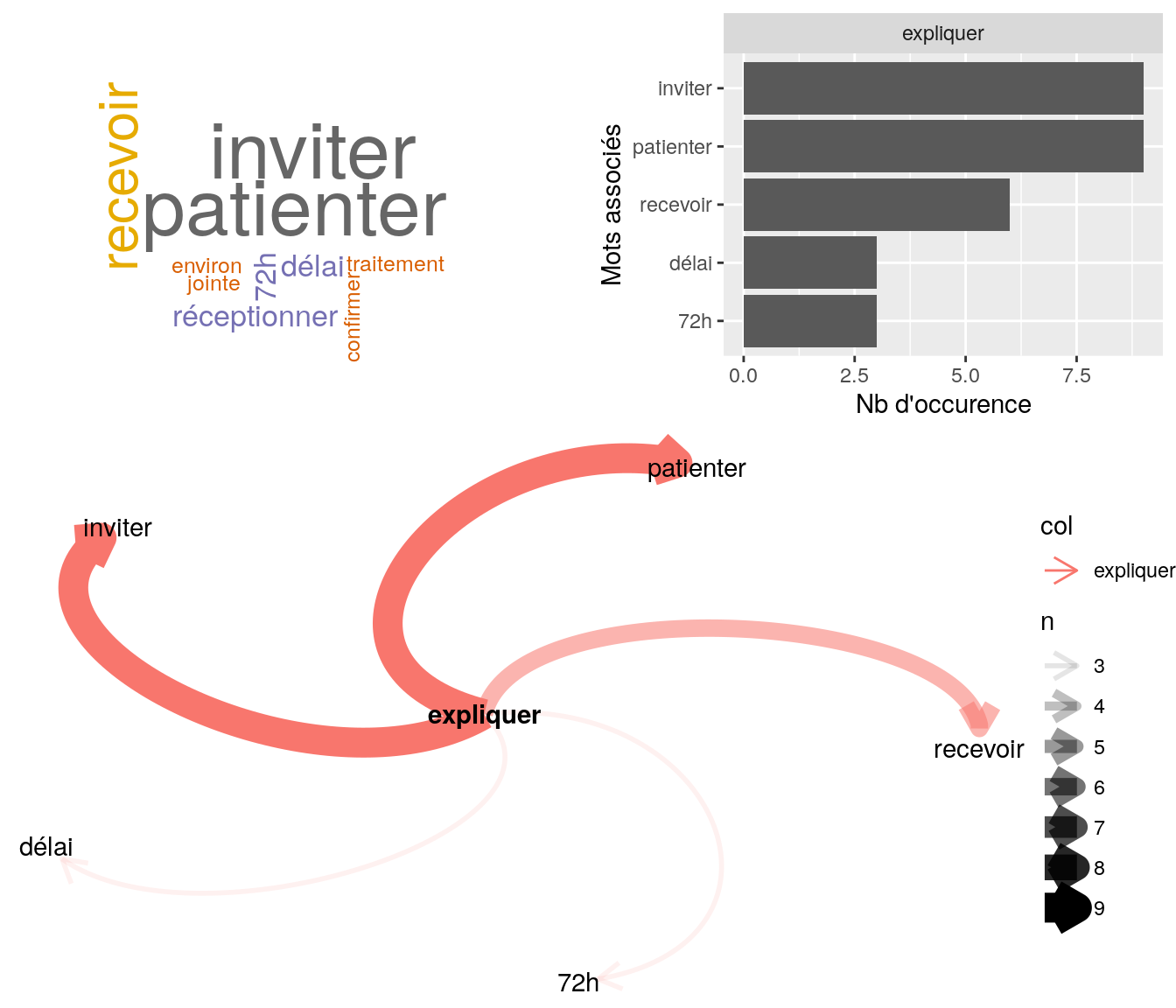
Figure 4.31: Statistiques descriptives liées aux nombres de mots associés au mot “expliquer”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "j'ai expliquer a mme que l'on avait bien recu sa facture je l'invite a patienter"
[2] "j'ai expliquer a mme que l'on avait bien receptionner son devis je l'invite a patienter"
[3] "j'ai expliquer à mme que l'on avait bien reçu sa dde."
[4] "mr a eu le remb des frais dentaire le 18/05/17 r171371005354001 mais n a pas eu le remb de la transitoire lui ai expliquer qu il sagit d un acte non remb ss et la ss ne nous la pas transmis mr nous la fait parvenir via toutm l invite a patienter le re"
[5] "bonjour j'ai expliquer à mr que l'on avait bien reçu son devis je l'invite à patienter" 4.2.10.5.2 Corrélation
# browser()
# on choisit le mot
mot = "expliquer"
#
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:5]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()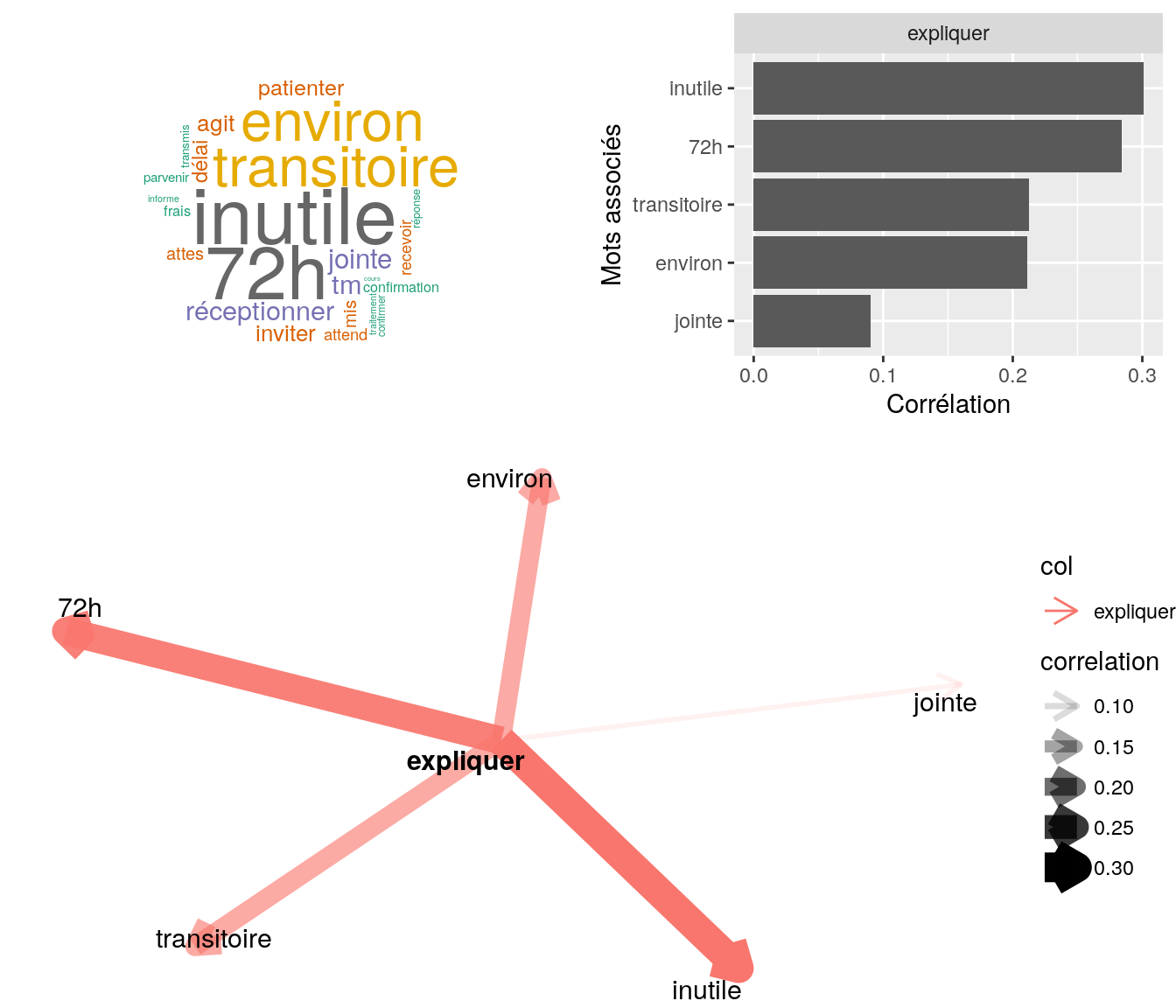
Figure 4.32: Statistiques descriptives liées corrélations associées au mot “expliquer”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "j'ai expliquer a mme que l'on avait bien recu sa facture je l'invite a patienter"
[2] "j'ai expliquer a mme que l'on avait bien receptionner son devis je l'invite a patienter"
[3] "j'ai expliquer à mme que l'on avait bien reçu sa dde."
[4] "mr a eu le remb des frais dentaire le 18/05/17 r171371005354001 mais n a pas eu le remb de la transitoire lui ai expliquer qu il sagit d un acte non remb ss et la ss ne nous la pas transmis mr nous la fait parvenir via toutm l invite a patienter le re"
[5] "bonjour j'ai expliquer à mr que l'on avait bien reçu son devis je l'invite à patienter" 4.2.10.6 “relance”
4.2.10.6.1 Comptage
# on choisit le mot
mot = "relance"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*1.3,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()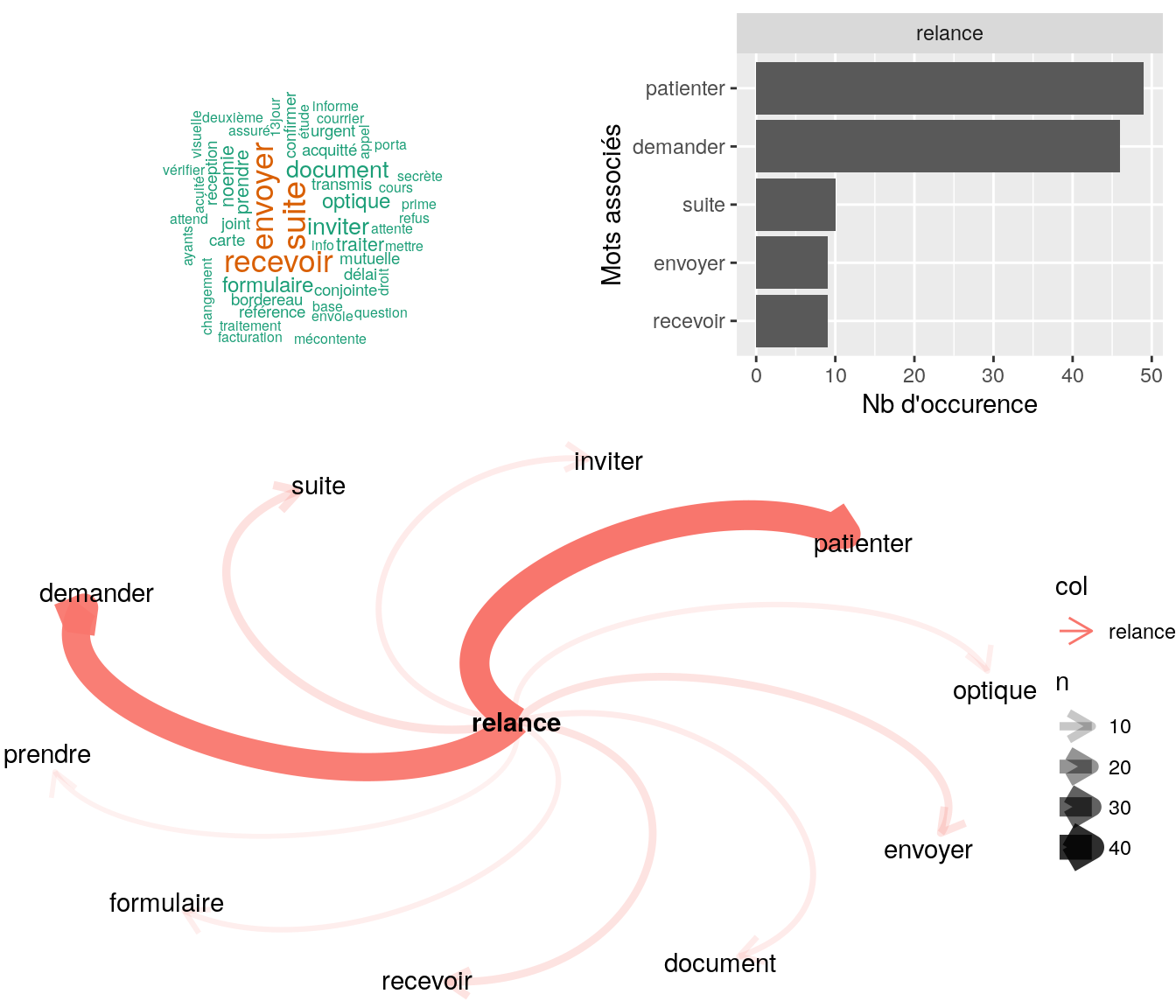
Figure 4.33: Statistiques descriptives liées aux nombres de mots associés au mot “relance”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mme nous contacte et souhaite savoir ou en est son dossier relance ok ai demandé de patienter"
[2] "merci de prendre la demande toutm 4414323 et la relance suite changement sd'acuité visuelle"
[3] "mme nous contacte et souhaite savoir ou en est son dossier relance ok ai demandé de patienter"
[4] "mr nous contacte et souhaite savoir ou en est son dossier relance ok ai demandé de patienter"
[5] "mme nous contacte et souhaite savoir ou en est son dossier relance ok ai informé que noemie est deja active"4.2.10.6.2 Corrélation
# on choisit le mot
mot = "relance"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.6,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()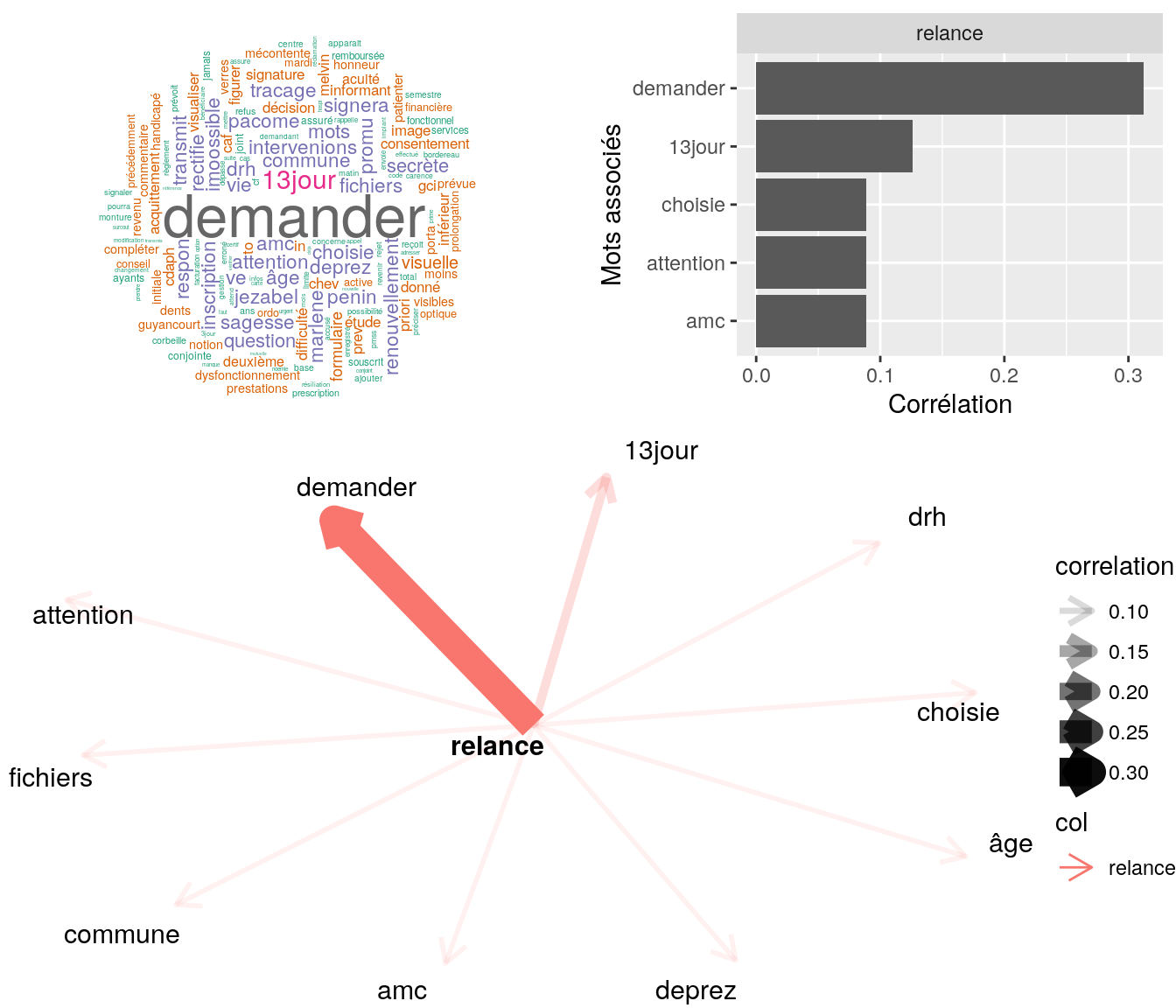
Figure 4.34: Statistiques descriptives liées corrélations associées au mot “relance”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mde relance la demande"
[2] "relance tel ce jour"
[3] "mme nous contacte et souhaite savoir ou en est son dossier relance ok ai demandé de patienter"
[4] "m. nous relance car nous avait envoyé via toutm decision cdaph + refus pole emploi pour prolongation des droit de jezabel réf : 4410869 réf : 4338621 un handicapé, de plus de 18 ans et sans limite d'âge, s'il a un revenu inférieur à 0% du pmss moins to"
[5] "mme nous contacte et souhaite savoir ou en est son dossier relance ok ai demandé de patienter pour l'étude de son devis" 4.2.10.7 “joindre”
4.2.10.7.1 Comptage
# on choisit le mot
mot = "joindre"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()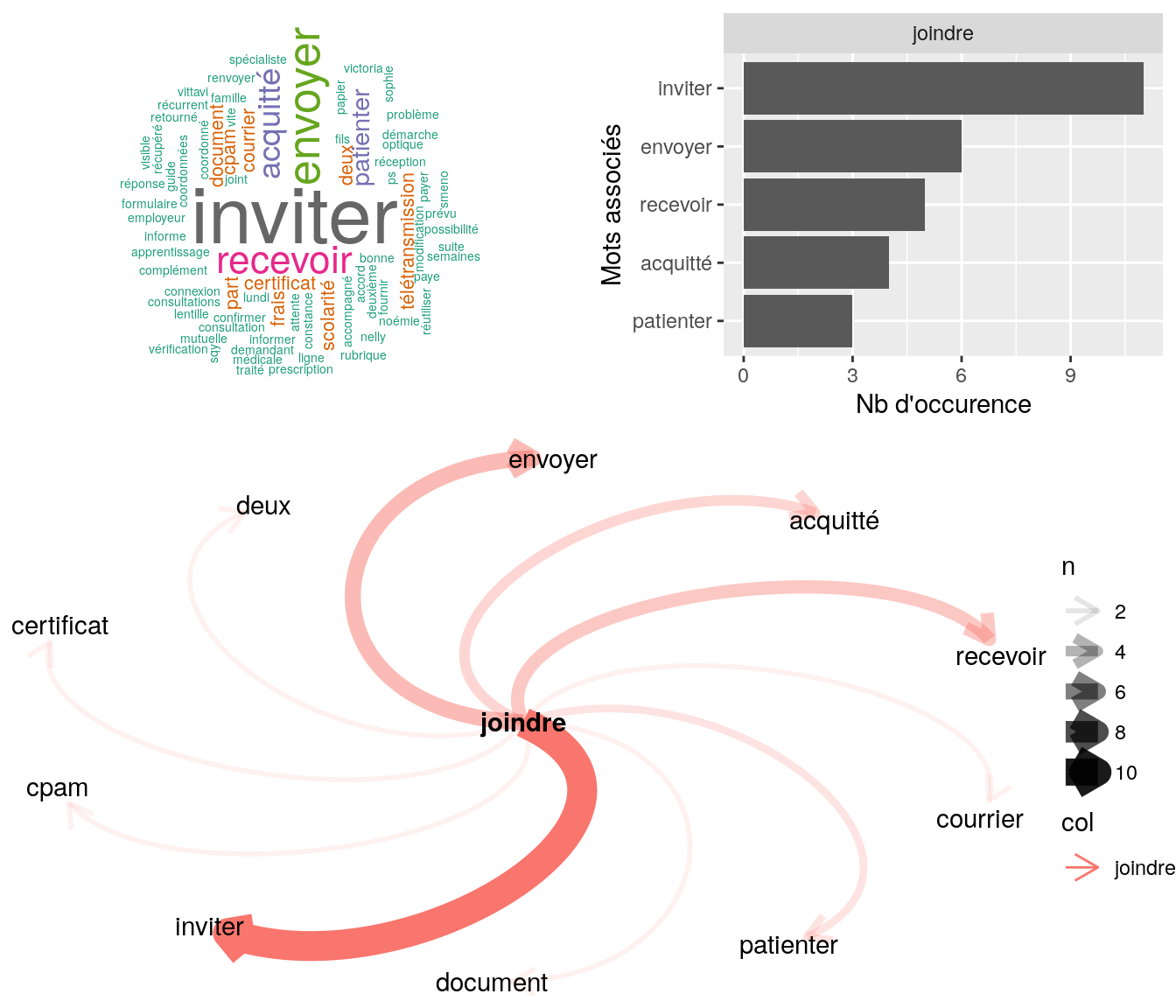
Figure 4.35: Statistiques descriptives liées aux nombres de mots associés à joindre
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "ai inviter a joindre decompte de ss car il on fait un remb au ps"
[2] "monsieur souhaite que son dossier soit traité pour modif du n° de ss invite à patienter et de joindre décompte de ss + facture aquittée pour être rbsé"
[3] "mme et mr en ligne, m'indique qu'il y a un problème récurrent avec l'espace toutm et qu'ils n'ont pas la possibilité de joindre le devis merci de leur fournir la réponse de notre estimation de remboursement au plus vite, consultation prévu lundi 18/12/"
[4] "mme nous a envoyer 3 facture acquitée pour les consultations de specialiste souhaite savoir si on l'a bien recu ai invité a patienter ai inviter a nous joindre la facture pour victoria"
[5] "mme nous enovyer des factures par toutm souhaite savoir si on l'a recu, mme a payer la part mutuelle ai informer facture recu le 10/04/2017, ai inviter a recupéré les decomptes de ss et nous le joindre depuis toutm des qu'on lui demande" 4.2.10.7.2 Corrélation
# on choisit le mot
mot = "joindre"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.4,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()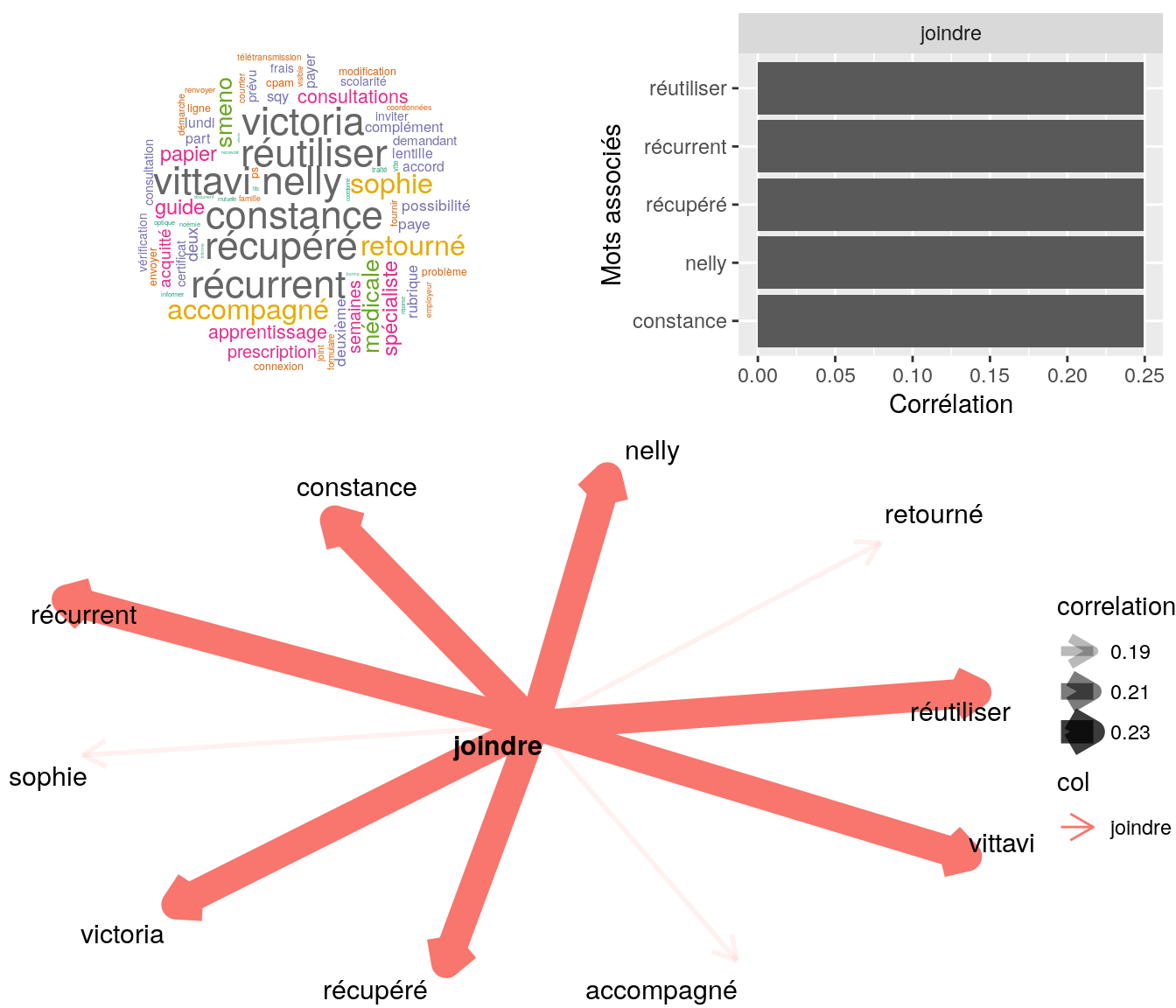
Figure 4.36: Statistiques descriptives liées corrélations associées à “joindre”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "bjr, mme souhaite svaoir si recu devis , aperes accord de mme et verification des devis mme nous a joitn deux fois el me invite a joindre deuxieme devis cdlt"
[2] "bonjour, mme souhaite savoir dans quelle rubrique sur toutm elle doit joindre l'attestation de droits ss pour l'affiliation de son fils. l'invite à renvoyer cette attestation par courrier papier à sqy avec l'attestation de monsieur, la sienne, le rib et"
[3] "mr n'a pas reçu le rbt des frais de lentilles - a reçu un courrier demandant de joindre à la facture aquitée la prescription médicale - mr a retourné les documents accompagné du courrier il y 3 semaines - pas de remboursements visible sur cms - mr nous"
[4] "mme nous a envoyé le certificat de scolarité + contrat d'apprentissage via toutm , souhaite savoir si on l'a recu ai informé qu'on n'a recu deux fois le certificat de scolarité mais pas de contrat d'apprentissage ai invité a nous le joindre via toutm"
[5] "mme nous enovyer des factures par toutm souhaite savoir si on l'a recu, mme a payer la part mutuelle ai informer facture recu le 10/04/2017, ai inviter a recupéré les decomptes de ss et nous le joindre depuis toutm des qu'on lui demande" 4.2.10.8 “parvenir”
4.2.10.8.1 Comptage
# on choisit le mot
mot = "parvenir"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()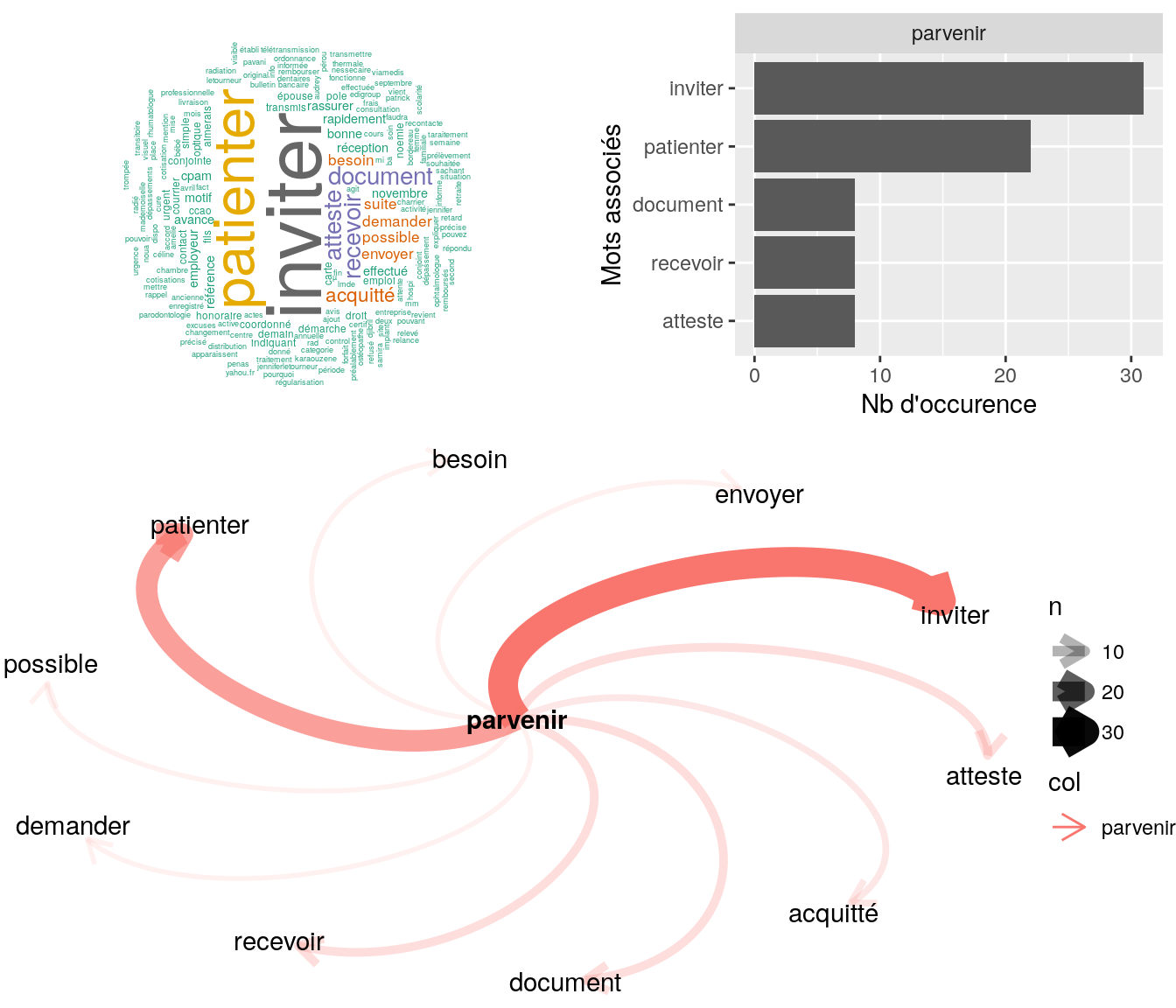
Figure 4.37: Statistiques descriptives liées aux nombres de mots associés à parvenir
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mrs aimerais savoir ou en est sa demande car portabilité bien demandé\"\" par l'employeur mrs a un bulletin de portabilité qu'il va nous faire parvenir via toutm le plus rapidement possible"
[2] "mme nous contact car depuis le mois de novembre sont contrat et radié car le prelvement n'a pas ete effectué mme a bien le prelvement sur son compte bancaire ai invité a nous faire parvenir releve bancaire avec prelvement"
[3] "ai rassurer mr sur la bonne reception des justificatifs invite a nous faire parvenir l attest de ss"
[4] "bjr, merci de faire parvenir à melle penas samira une attestation d'aff par mail mail ok cdlt"
[5] "mme a fait parvenir facture rhumato l invite a patienter" 4.2.10.8.2 Corrélation
# on choisit le mot
mot = "parvenir"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.3,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()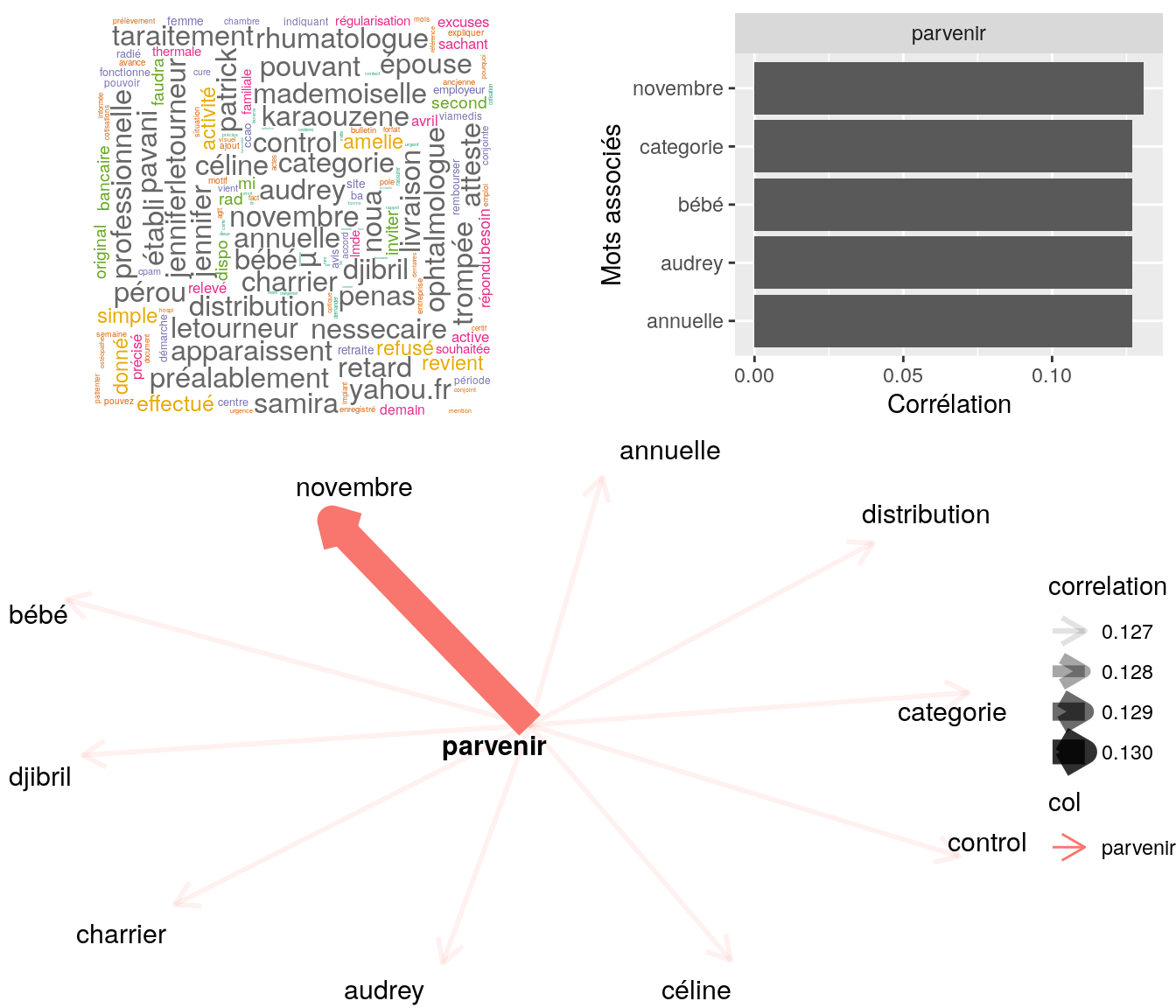
Figure 4.38: Statistiques descriptives liées corrélations associées à “parvenir”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr souhaite savoir savoir pourquoi tl n a pas fonctionne pas de chmt cpam tl toujours active ai invite mr a nous faire parvenir decomptes ss et factures acquitees"
[2] "mr a fait parvenir attest pole emploi concernant sa fille audrey qui n est plus sur son contrat l invite a patienter"
[3] "bonjour , mr nous rappel pour la meme demande toujours en attente invite à patienter informe qu'une fois que la maj du centre ss effectuée il faudra nous faire parvenir decompte ss et facture acquittée pour pouvoir se faire rembourser excuses p"
[4] "bjr, ai invité mme à faire parvenir une facture acquittée avec mention chambre et non forfait cdlt"
[5] "mme a fait parvenir attest ss + act de naissance pour affiliation de son bebe l invite a patienter" 4.2.10.9 “recevoir”
4.2.10.9.1 Comptage
# on choisit le mot
mot = "recevoir"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCount[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCount[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.6,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCount[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()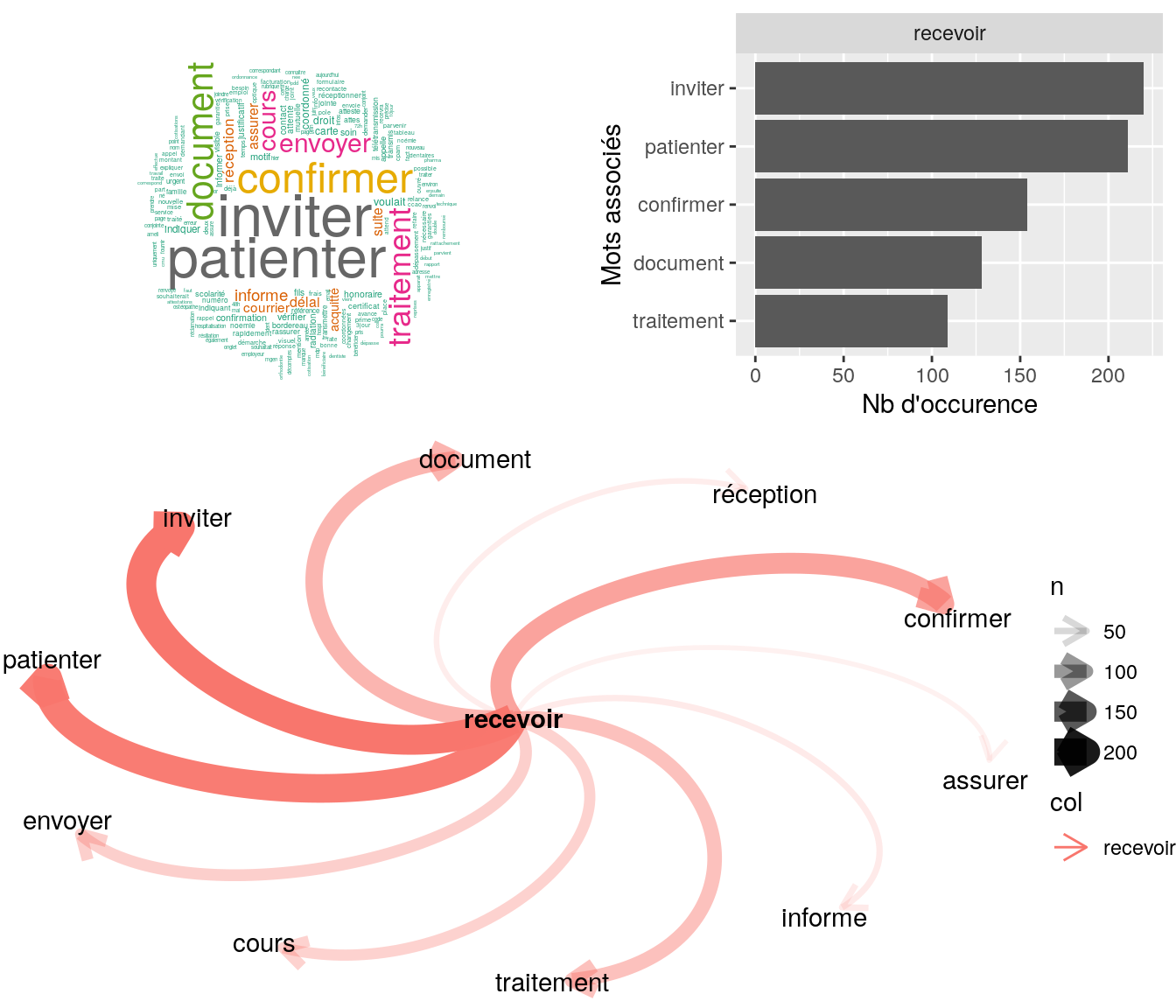
Figure 4.39: Statistiques descriptives liées aux nombres de mots associés à recevoir
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr souhaite savoir si bien recu les 9 documents ai indiquer oui mr souhaite recevoir mail indiquant demande traite cms ok merci cdlt"
[2] "madame souhaite recevoir ce document par email j'ai demandé de aptienter pour le traitement de sa demande"
[3] "confirme a mme devis bien reçu//va recevoir rép par mail au plus tard demain"
[4] "mme souhaite recevoir une attestation de radiation par mail la concernant ainsi que mr / merci de faire le necessaire invite mme a patienter"
[5] "bonjour mme souhaite recevoir par mail attestation d affiliation pour elle meme et l ensemble des ayant droits merci" 4.2.10.9.2 Corrélation
# on choisit le mot
mot = "recevoir"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(wordCor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = wordCor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.6,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(wordCor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()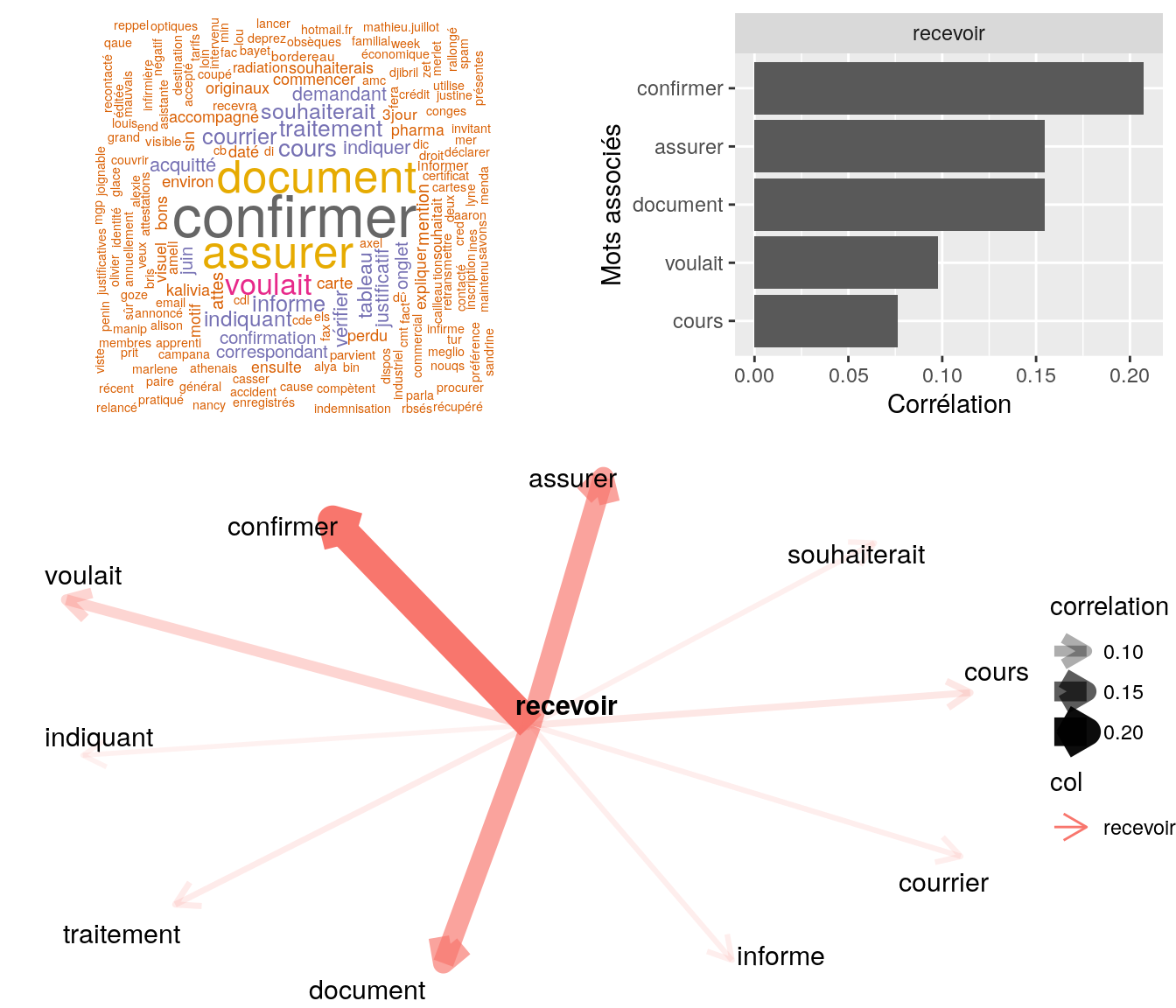
Figure 4.40: Statistiques descriptives liées corrélations associées à “recevoir”
# table
relan(mot, nb = 5, exact = TRUE)$commentaire
[1] "mr souhaite suprrimer mme des ayants-droits, courrier visible via ged 20170824_1_cr_aff_019_0013 // invite mr a patienter // mr souahite recevoir par la suite une attestatio de radiaiton par mail / merci de faire le necessaire"
[2] "mr souhaite recevoir par mail une attestation d'affiliation à caractère obligatoire avc la mention \"\"famille\"\" concernant son fils / invite mr a patienter"
[3] "mr souhaite recevoir par mail de preference"
[4] "bjr, mr nous contacte car ne souhaite pas le remboursement des soins en piéces jointes à sa demande toutm mais une attestation de non remboursement pour ceux-ci. il souhaite recevoir le document par mail. ai invité à patienter et à suivre sa demande via"
[5] "mme nous contacte car on lui à indiquée hier 15 min pour recevoir estimation indique à mme min 48h invite à patientée" 4.2.11 Association “inviter - patienter”
Ici, à cause d’un problème d’encodage (https://github.com/juliasilge/tidytext/issues/80), je ne peux pas utiliser la fonction unnest_tokens, qui m’aurait permis de compter et d’identifier les fois où le mot “inviter” est devancé ou précédé par le mot “patienter”. Au lieu de ça, j’ai fait l’hypothèse qu’à chaque fois que l’on rencontre le mot “patienter” et “inviter” dans le même commentaire, c’est qu’il faisait parti de l’expression “invité à patienter”.
# relance avec le mot "inviter"
ind.inviter = dataset1NVtidy[trad == "inviter",relance]
# relance avec le mot "patienter"
ind.patienter = dataset1NVtidy[trad == "patienter",relance]
# relance avec les deux mots présents
ind.association = intersect(ind.inviter,ind.patienter)
# données fictive ...
invpatOcur = data.table(trad = "inviter-patienter",
relance = ind.association,
n = 1)
# ... à rattacher au tableau des occurences
Ocur = rbind(wordOcur[! trad %in% c("patienter", "inviter"),], invpatOcur)
# matrice des corrélations entre mots
Cor = as.data.table(pairwise_cor(Ocur,
trad,
relance,
sort = TRUE))
# matrice des corrélations entre mots
Count = as.data.table(pairwise_count(Ocur,
trad,
relance,
sort = TRUE))4.2.11.1 Comptage
# on choisit le mot
mot = "inviter-patienter"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(Count[item1 == mot, ][order(-n), .SD[1:5]], n)
ggplotted = ggplot(dataPlot, aes(item2, n)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Nb d'occurence") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = Count[item1 == mot, .(n = n,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.8,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(Count[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "fr") +
geom_edge_arc(aes(edge_alpha = n,
edge_width = n,
colour = col,
direction = "out"),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm')) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")))+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()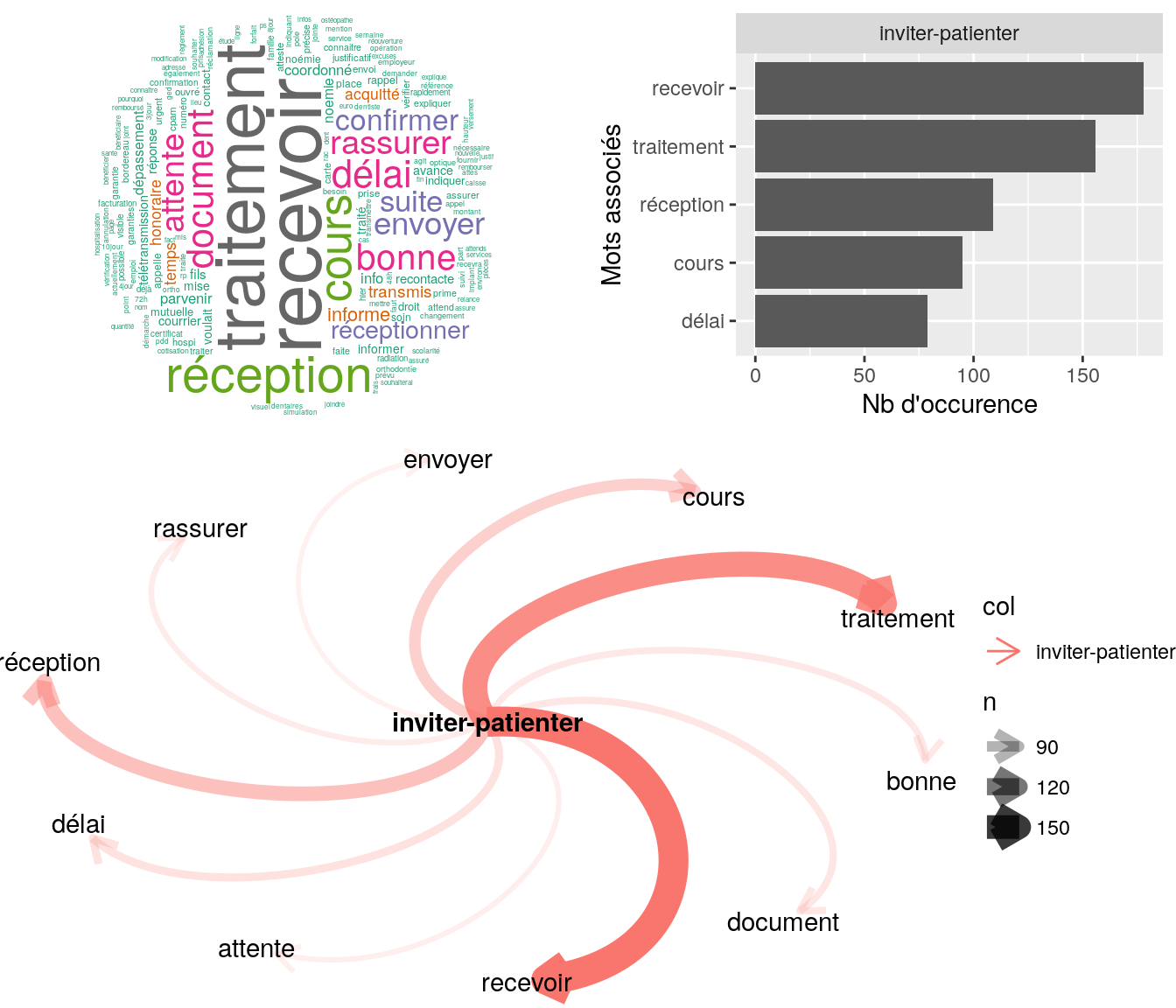
Figure 4.41: Statistiques descriptives liées aux nombres de mots associés à l association “inviter-patienter”
4.2.11.2 Corrélation
# on choisit le mot
mot = "inviter-patienter"
# on démarre un plot
plot.new()
# on configure le nombre de plot
gl = grid.layout(nrow=7, ncol=2)
# on configure la "vue" des plots
vp.1 <- viewport(layout.pos.col=1, layout.pos.row=c(1:3))
vp.2 <- viewport(layout.pos.col=2, layout.pos.row=c(1:3))
vp.3 <- viewport(layout.pos.col=c(1:2), layout.pos.row=c(4:7))
# initialisation des plots
pushViewport(viewport(layout=gl))
# premier plot
pushViewport(vp.1)
# nouvelle base graphique pour le premier graph
par(new=TRUE, fig=gridFIG())
dataPlot = setorder(Cor[item1 == mot, ][order(-correlation), .SD[1:5]], correlation)
ggplotted = ggplot(dataPlot, aes(item2, correlation)) +
geom_bar(stat = "identity") +
scale_x_discrete(limits = dataPlot[, item2])+
coord_flip() +
labs(x = "Mots associés", y = "Corrélation") +
facet_grid(.~item1)
# done with the first viewport
popViewport()
# move to the next viewport
pushViewport(vp.2)
dataPlot = Cor[item1 == mot, .(n = correlation,
trad = item2)]
set.seed(1234)
wordcloud(words = dataPlot$trad,
freq = dataPlot$n,
min.freq = quantile(dataPlot$n,0.75),
max.words=200,
random.order=FALSE,
rot.per=0.35,
scale=c(3.5,0.25)*0.4,
colors=brewer.pal(8, "Dark2"))
# print our ggplot graphics here
print(ggplotted, newpage = FALSE)
# done with this viewport
popViewport()
# move to the next viewport
pushViewport(vp.3)
# création d'un igraph
dataPlot = graph_from_data_frame(Cor[item1 %in% c(mot),][,.SD[1:10]][,col:=item1])
# custom
ggplotted2 = ggraph(dataPlot,
layout = "dh") +
geom_edge_link(aes(edge_alpha = correlation,
edge_width = correlation,
colour = col),
arrow = arrow(length = unit(4, 'mm')),
end_cap = circle(3, 'mm'),
show.legend = TRUE) +
geom_node_text(aes(label = name,
fontface = ifelse(name %in% c(mot),"bold","plain")),
repel = TRUE,
size=4)+
theme_void()
# print our ggplot graphics here
print(ggplotted2, newpage = FALSE, vp = vp.3)
# done with this viewport
popViewport()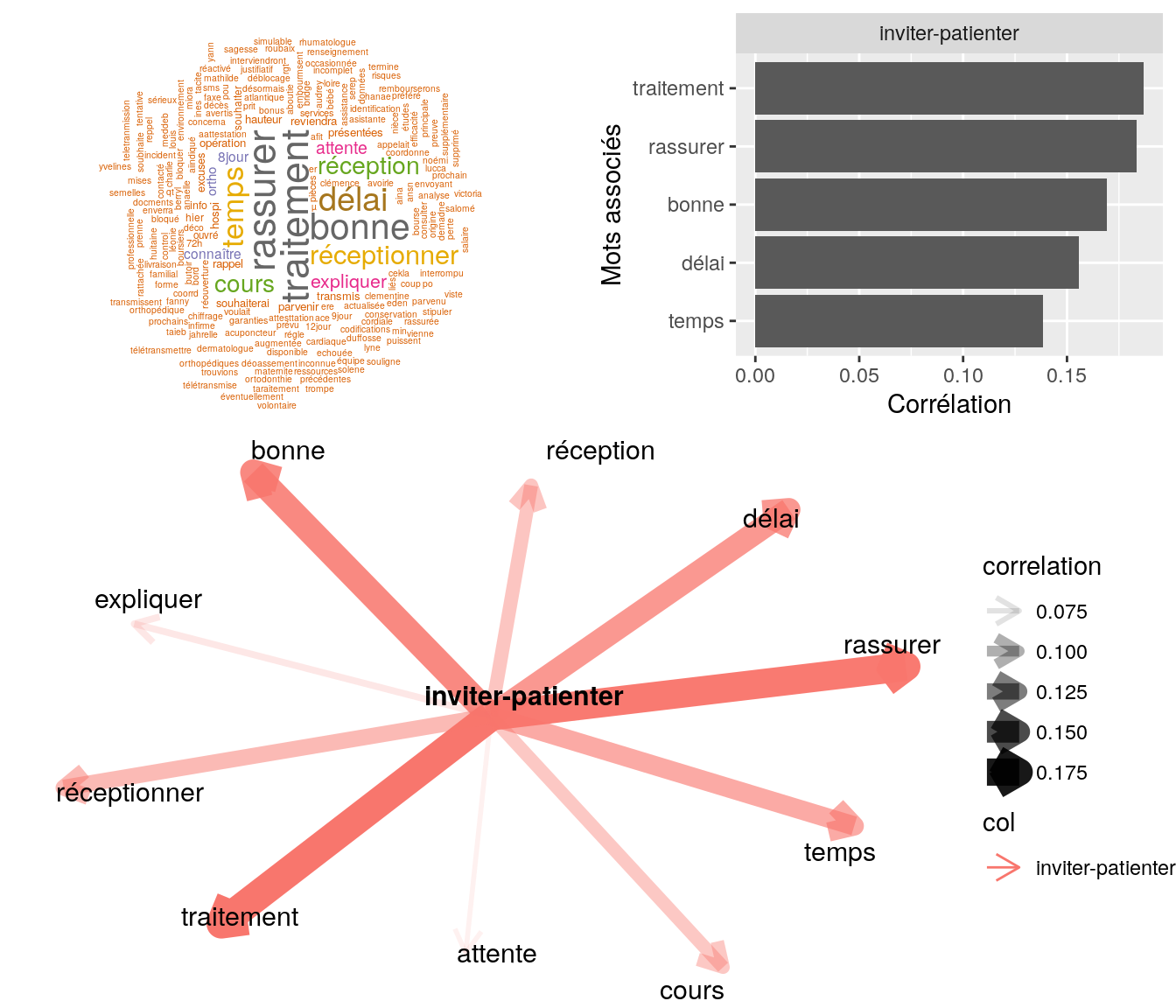
Figure 4.42: Statistiques descriptives liées corrélations associées à l association “inviter-patienter”
4.3 Clustering
Cette partie est plus ou moins un copié-collé de l’une des parties du site/livre Text Mining with R, dans laquelle les auteurs étudient la possibilité de regrouper des mots issues de documents de la NASA sous la forme de différents sujets. L’idée ici est d’utilisé la modélisation de sujet (ou topic modeling), qui considère un document (ou dans notre cas, un commentaire) comme un mélange de thèmes et un thème comme un mélange de mots. Ici on va utiliser l’ allocation de Dirichlet latente pour la modélisation de nos thèmes.
Dans un premier temps, on doit transformer nos données pour obtenir une matrice mot-relance (ou document-term matrix), comme sur la vidéo ci-dessus.
# nombre de mots par mots et relances
word_counts = dataset1NVtidy[, .(n = .N), by = .(relance, trad)]
# création de la matrice
desc_dtm = cast_dtm(word_counts, relance, trad, n)Ensuite on lance la modélisation des sujets, en spécifiant le nombre de sujets escomptés. Ici j’ai choisi trois, en me basant sur les discutions que l’on a eu en équipe lors des précédents travaux.
# c'est la que la magie apparait !
desc_lda = LDA(desc_dtm, k = 3,
control = list(seed = 1234)) # par souci de reproductibilité, on fixe la part aléatoire
# pour rendre ce nouvel objet compréhensible, on le convertit
tidy_lda = tidy(desc_lda)
tidy_ldaLa colonne beta correspond à la probabilité que le mot considéré soit associé à un sujet. Vue qu’il s’agit d’une probabilité, celle-ci devrait théoriquement varier entre 0 et 1. Or ici, la probabilité que nos mots soient associées à l’un des trois sujets varie entre 0 et 0.11. Ca n’est pas vraiment bon signe !
Regardons maintenant la distribution d’une autre probabilité, gamma, qui correspond à la probabilité d’un commentaire d’être associé à un sujet.
# extraction des probabilités
lda_gamma = tidy(desc_lda, matrix = "gamma")
# plot
ggplot(lda_gamma, aes(gamma)) +
geom_histogram() +
scale_y_log10() +
labs(y = "Nombre de commentaires",
x = expression(gamma))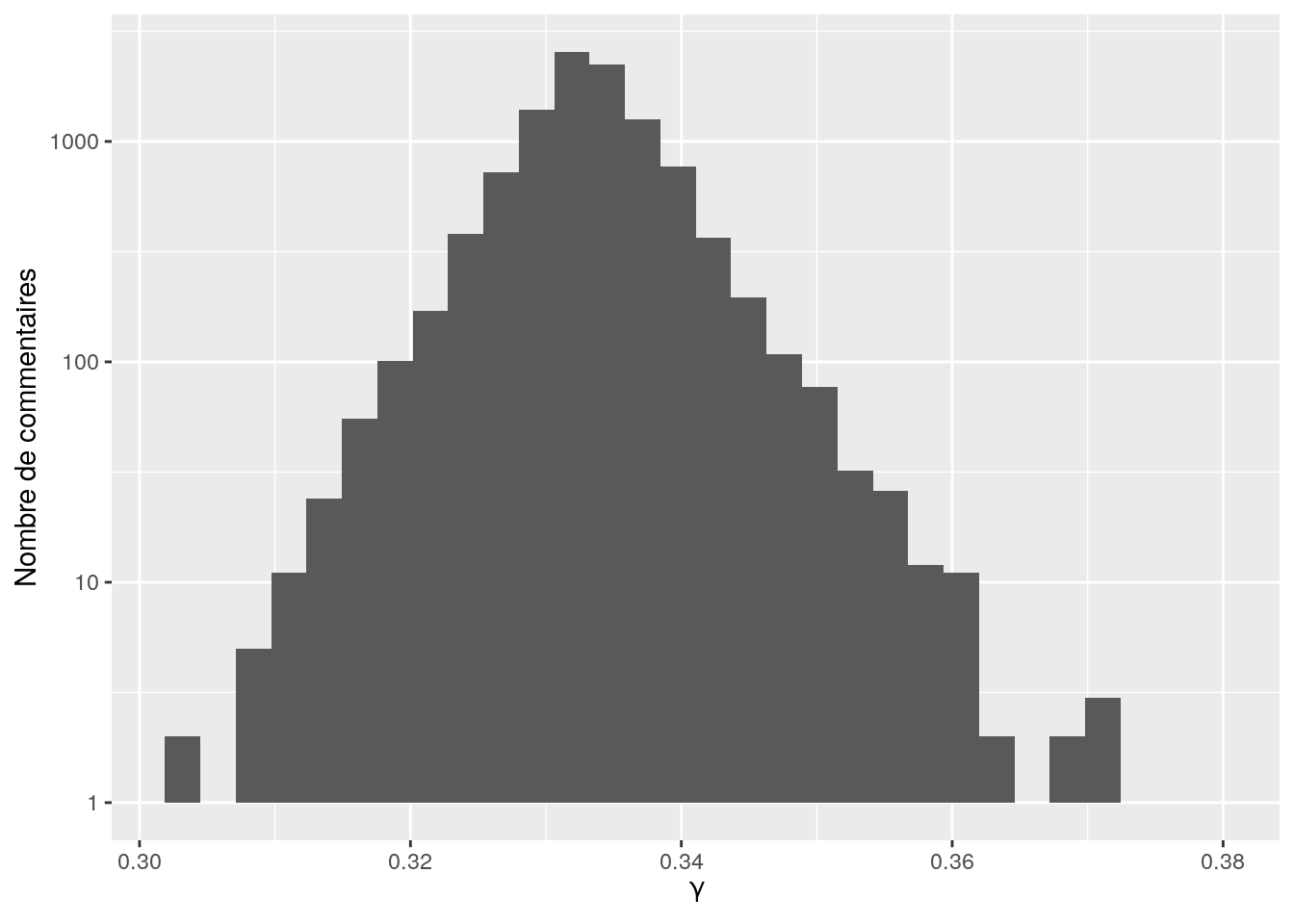
Figure 4.43: Distribution de la probablité que les mots soient associés à l’un des sujets.
Ici, on se serait plutôt attendu à un nombre de commentaires quasiment constant en fonction des probabilités…
Ces résultats ne sont pas vraiment probants, autrement dit j’ai une confiance moyenne dans leur significativité. Jettons quand même un coup d’oeil au Top 10 des mots qui composent les sujets de notre corpus, en faisant varier le nombre de sujet à identifier de 2 à 5.
4.3.1 k = 2
# c'est la que la magie apparait !
desc_lda = LDA(desc_dtm, k = 2,
control = list(seed = 1234)) # par souci de reproductibilité, on fixe la part aléatoire
# pour rendre ce nouvel objet compréhensible, on le convertit
tidy_lda = tidy(desc_lda)
# top 10 des termes ayant la probabilité beta la plus importante par thème
top_terms = tidy_lda %>%
group_by(topic) %>%
top_n(20, beta) %>%
ungroup() %>%
arrange(topic, -beta)
# plot jeu de données
dataPlot = top_terms %>%
mutate(term = reorder(term, beta)) %>%
group_by(topic, term) %>%
arrange(desc(beta)) %>%
ungroup() %>%
mutate(term = factor(paste(term, topic, sep = "__"),
levels = rev(paste(term, topic, sep = "__"))))
# identification des uniques
dataPlot = as.data.table(dataPlot)
listWord = dataPlot[,term2 := gsub("__.+$", "", term)][,.(n = .N,
term = term), term2][n==1, term]
# plot
plotList=list()
for (i in dataPlot[,unique(topic)]){
plotList[[i]]=ggplot(dataPlot[topic==i,][,col:= term %in% listWord],
aes(x = term,
y = beta,
fill = col,
col = col)) +
scale_fill_manual(values=c("grey","white"))+
scale_color_manual(values=c("grey","red"))+
geom_bar(stat="identity")+
scale_x_discrete(labels = function(x) gsub("__.+$", "", x))+
labs(x = NULL, y = expression(beta)) +
theme(legend.position = "none")+
coord_flip()+
facet_grid(~topic)
}
do.call(grid.arrange,c(plotList,ncol=dataPlot[,length(unique(topic))]))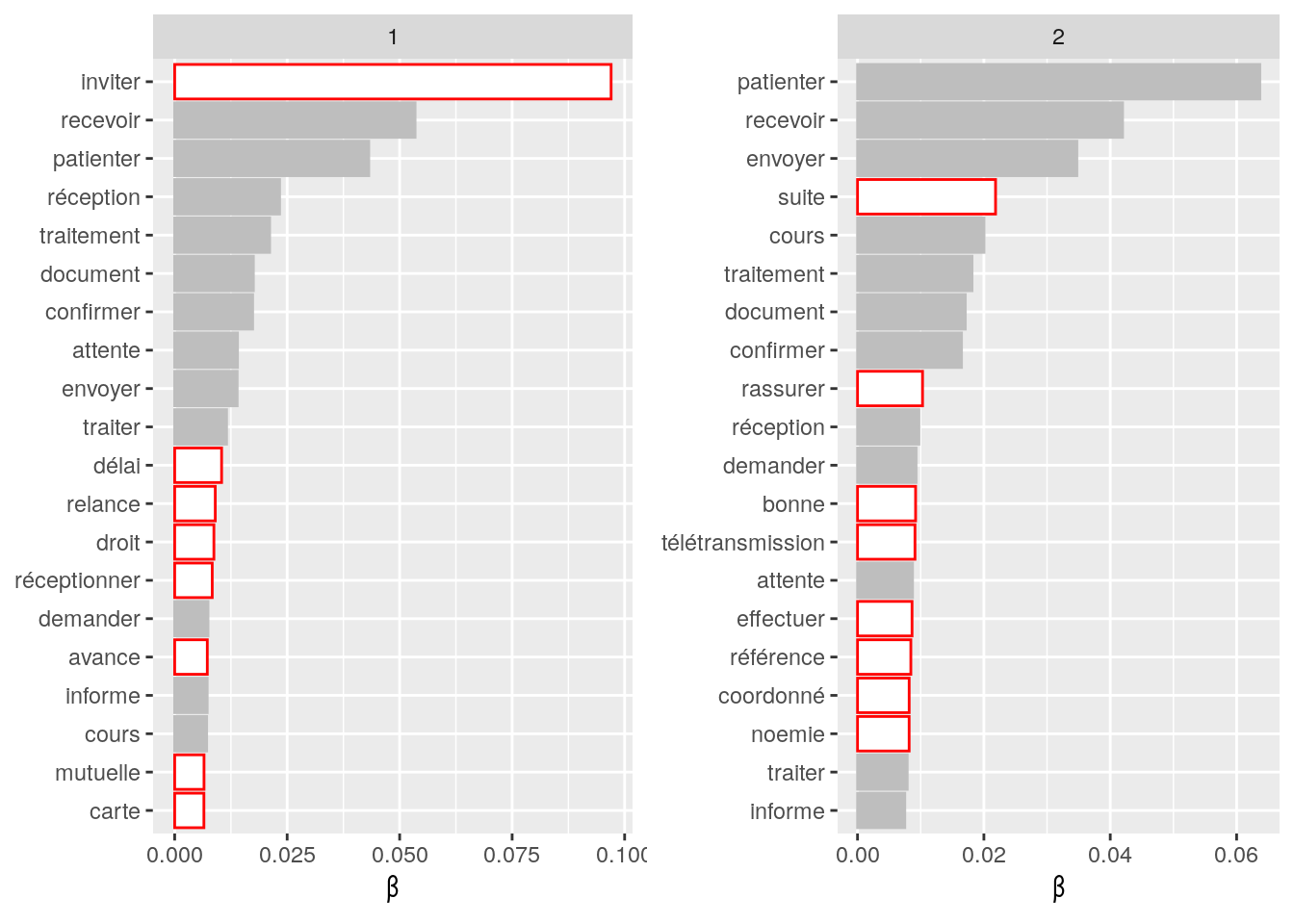
Figure 4.44: Top 20 des mots associés aux différents sujets. En rouge correspondent les mots qui ne sont présents que dans un seul sujet.
4.3.2 k = 3
# c'est la que la magie apparait !
desc_lda = LDA(desc_dtm, k = 3,
control = list(seed = 1234)) # par souci de reproductibilité, on fixe la part aléatoire
# pour rendre ce nouvel objet compréhensible, on le convertit
tidy_lda = tidy(desc_lda)
# top 10 des termes ayant la probabilité beta la plus importante par thème
top_terms = tidy_lda %>%
group_by(topic) %>%
top_n(20, beta) %>%
ungroup() %>%
arrange(topic, -beta)
# plot jeu de données
dataPlot = top_terms %>%
mutate(term = reorder(term, beta)) %>%
group_by(topic, term) %>%
arrange(desc(beta)) %>%
ungroup() %>%
mutate(term = factor(paste(term, topic, sep = "__"),
levels = rev(paste(term, topic, sep = "__"))))
# identification des uniques
dataPlot = as.data.table(dataPlot)
listWord = dataPlot[,term2 := gsub("__.+$", "", term)][,.(n = .N,
term = term), term2][n==1, term]
# plot
plotList=list()
for (i in dataPlot[,unique(topic)]){
plotList[[i]]=ggplot(dataPlot[topic==i,][,col:= term %in% listWord],
aes(x = term,
y = beta,
fill = col,
col = col)) +
scale_fill_manual(values=c("grey","white"))+
scale_color_manual(values=c("grey","red"))+
geom_bar(stat="identity")+
scale_x_discrete(labels = function(x) gsub("__.+$", "", x))+
labs(x = NULL, y = expression(beta)) +
theme(legend.position = "none")+
coord_flip()+
facet_grid(~topic)
}
do.call(grid.arrange,c(plotList,ncol=dataPlot[,length(unique(topic))]))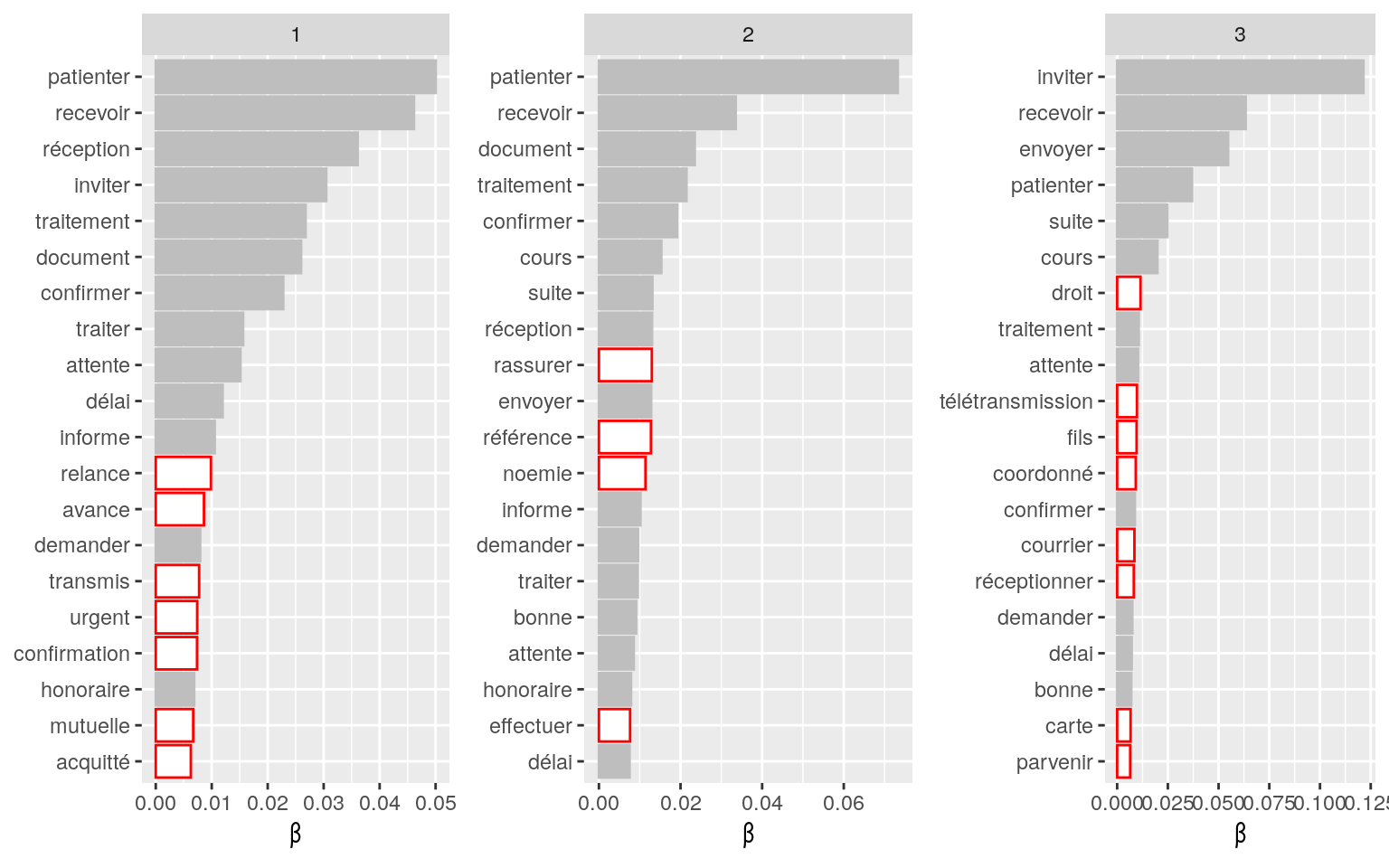
Figure 4.45: Top 20 des mots associés aux différents sujets. En rouge correspondent les mots qui ne sont présents que dans un seul sujet.
4.3.3 k = 4
# c'est la que la magie apparait !
desc_lda = LDA(desc_dtm, k = 4,
control = list(seed = 1234)) # par souci de reproductibilité, on fixe la part aléatoire
# pour rendre ce nouvel objet compréhensible, on le convertit
tidy_lda = tidy(desc_lda)
# top 10 des termes ayant la probabilité beta la plus importante par thème
top_terms = tidy_lda %>%
group_by(topic) %>%
top_n(20, beta) %>%
ungroup() %>%
arrange(topic, -beta)
# plot jeu de données
dataPlot = top_terms %>%
mutate(term = reorder(term, beta)) %>%
group_by(topic, term) %>%
arrange(desc(beta)) %>%
ungroup() %>%
mutate(term = factor(paste(term, topic, sep = "__"),
levels = rev(paste(term, topic, sep = "__"))))
# identification des uniques
dataPlot = as.data.table(dataPlot)
listWord = dataPlot[,term2 := gsub("__.+$", "", term)][,.(n = .N,
term = term), term2][n==1, term]
# plot
plotList=list()
for (i in dataPlot[,unique(topic)]){
plotList[[i]]=ggplot(dataPlot[topic==i,][,col:= term %in% listWord],
aes(x = term,
y = beta,
fill = col,
col = col)) +
scale_fill_manual(values=c("grey","white"))+
scale_color_manual(values=c("grey","red"))+
geom_bar(stat="identity")+
scale_x_discrete(labels = function(x) gsub("__.+$", "", x))+
labs(x = NULL, y = expression(beta)) +
theme(legend.position = "none")+
coord_flip()+
facet_grid(~topic)
}
do.call(grid.arrange,c(plotList,ncol=dataPlot[,length(unique(topic))]))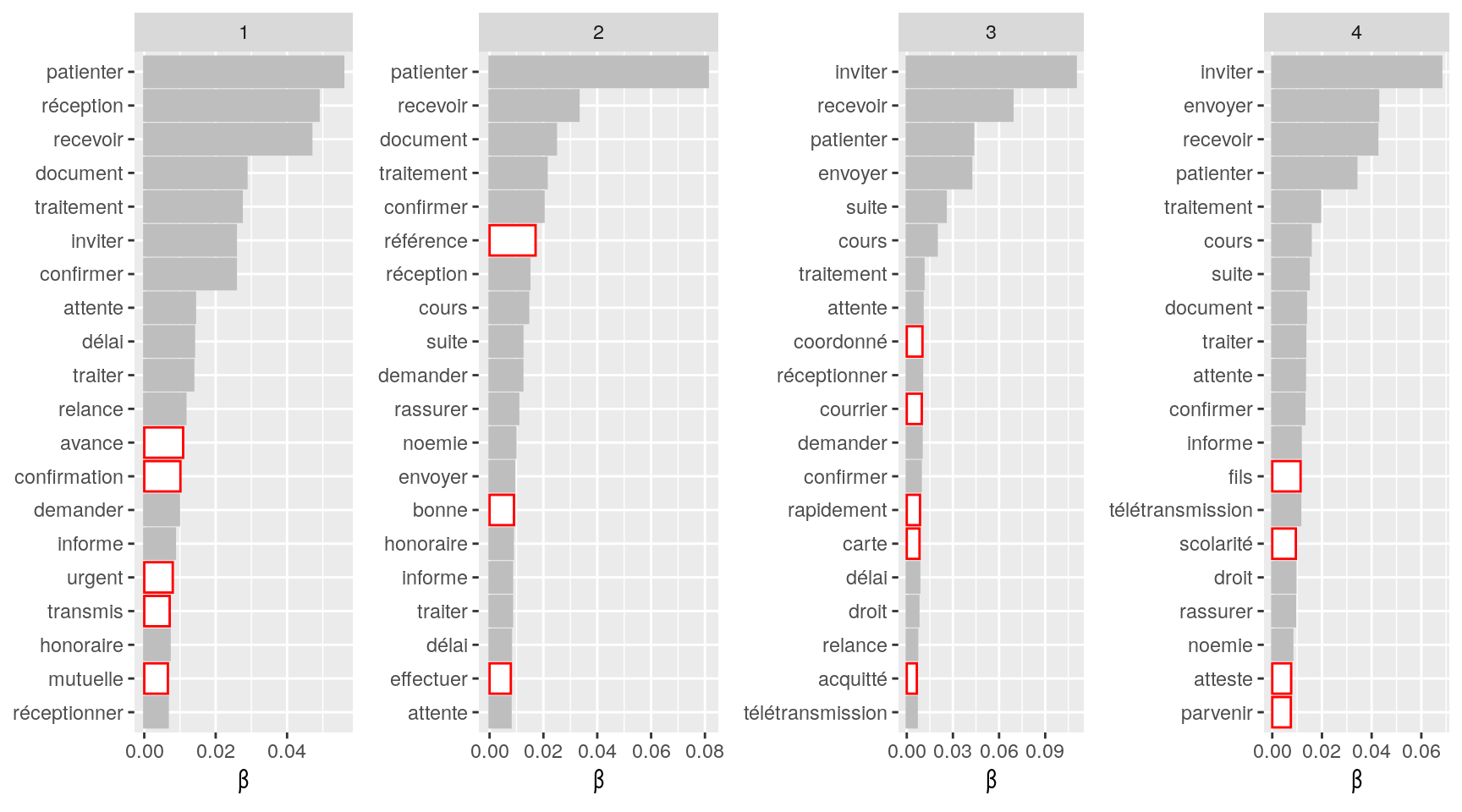
Figure 4.46: Top 20 des mots associés aux différents sujets. En rouge correspondent les mots qui ne sont présents que dans un seul sujet.
4.3.4 k = 5
# c'est la que la magie apparait !
desc_lda = LDA(desc_dtm, k = 5,
control = list(seed = 1234)) # par souci de reproductibilité, on fixe la part aléatoire
# pour rendre ce nouvel objet compréhensible, on le convertit
tidy_lda = tidy(desc_lda)
# top 10 des termes ayant la probabilité beta la plus importante par thème
top_terms = tidy_lda %>%
group_by(topic) %>%
top_n(20, beta) %>%
ungroup() %>%
arrange(topic, -beta)
# plot jeu de données
dataPlot = top_terms %>%
mutate(term = reorder(term, beta)) %>%
group_by(topic, term) %>%
arrange(desc(beta)) %>%
ungroup() %>%
mutate(term = factor(paste(term, topic, sep = "__"),
levels = rev(paste(term, topic, sep = "__"))))
# identification des uniques
dataPlot = as.data.table(dataPlot)
listWord = dataPlot[,term2 := gsub("__.+$", "", term)][,.(n = .N,
term = term), term2][n==1, term]
# plot
plotList=list()
for (i in dataPlot[,unique(topic)]){
plotList[[i]]=ggplot(dataPlot[topic==i,][,col:= term %in% listWord],
aes(x = term,
y = beta,
fill = col,
col = col)) +
scale_fill_manual(values=c("grey","white"))+
scale_color_manual(values=c("grey","red"))+
geom_bar(stat="identity")+
scale_x_discrete(labels = function(x) gsub("__.+$", "", x))+
labs(x = NULL, y = expression(beta)) +
theme(legend.position = "none")+
coord_flip()+
facet_grid(~topic)
}
do.call(grid.arrange,c(plotList,ncol=dataPlot[,length(unique(topic))]))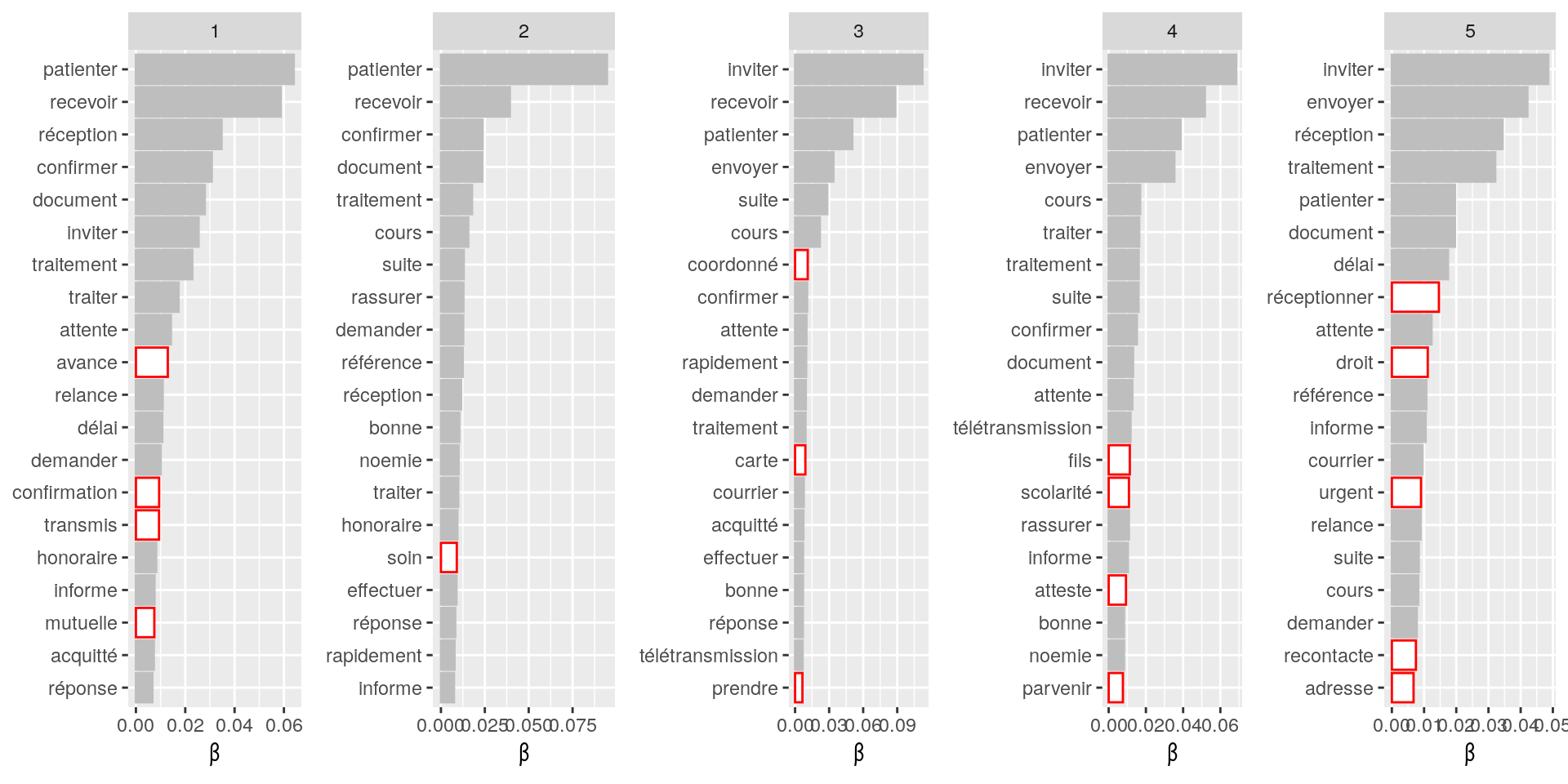
Figure 4.47: Top 20 des mots associés aux différents sujets. En rouge correspondent les mots qui ne sont présents que dans un seul sujet.
4.4 Evolution des thèmes
Afin de regarder l’évolution de la fréquence des différents thèmes identifiées, nous devons dans un premier temps réappliquer l’ensemble du traitement issu de la partie qui précède.
# sélection de toutes les inférieures à la limite défini par la règle des inter-quantiles (méthode pour supprimer les outliers)
IQR = dataset[, quantile(delay, 0.75) - quantile(delay, 0.25)]
dataset1 = dataset[delay < 1.5 * IQR + quantile(delay, 0.75), ]
# numérotation des relances de premier niveau
dataset1[, relance := 1:.N]
# lorsque "h" est rencontré tout seul, je supprime simplement l'espace le précédent
dataset1[,COMMENTAIRE_TRT:=gsub(" h ",
"h ",
COMMENTAIRE_TRT,
ignore.case = TRUE)]
# remplacement des formes "N jour" avec un espace
dataset1[,COMMENTAIRE_TRT:=gsub(paste0("(\\d)(\\s)(",regexpJour,")",
collapse=""),
"\\1jour",
COMMENTAIRE_TRT,
ignore.case = TRUE)]
# remplacement des formes "Njour" sans un espace
dataset1[,COMMENTAIRE_TRT:=gsub(paste0("(\\d)(",regexpJour,")",collapse=""),
"\\1jour",
COMMENTAIRE_TRT,
ignore.case = TRUE)]
# isolation de chacun des mots présents dans la zone de commentaire
dataset1tidy = unnest_tokens(dataset1, word, COMMENTAIRE_TRT, drop = FALSE)
# traduction des mots contenu dans notre corpus
dataset1tidy = merge(dataset1tidy,
dictionnaire,
by = "word",
all = TRUE,
sort = FALSE)
dataset1tidy = dataset1tidy[!is.na(DOMAINE), ][is.na(trad), trad := word]
# isolation de chacun des mots présents dans la traduction
dataset1tidy = unnest_tokens(dataset1tidy, trad, trad)
# suppression des lignes avec ou moins un chiffre présent dans le mot (exception faite de Xh et Xjour, où X est un chiffre ou un nombre)
dataset1tidy = dataset1tidy[! trad %like% "[0-9]" |
trad %like% "(\\d)jour$" |
trad %like% "(\\d)h$",]
# suppression des pronoms et conjonctions comprimés (en fait lorsqu'il y a une apostrophe, je ne garde que ce qu'il y a après)
dataset1tidy[trad != "aujourd'hui", trad:=gsub("^(.*[\\\'])", "", trad, ignore.case = TRUE)]Avant de supprimer tous les “stop-words” et autres mots parasites, nous devons associer les thèmes associés à chaque mot. Il est important de faire cette étape avant la suppression des mots parasites car certains de ces mots parasites peuvent être associés à d’autres mots clés permettant d’identitifier un thème, e.g “nous envoyer”.
# pour tous les mots qui ne servent pas pour la définition d'un thème on associe NA
dataset1tidy[, theme := as.numeric(NA)]
# theme 1 - Délai
dataset1tidy[trad %in% c("délai", "cours", "traitement", "ouvré", "temps", "préavis", "indiquer", "période", "environ", "attente") |
trad %like% "(\\d)jour$"|
trad %like% "(\\d)h$", theme := 1]
# theme 2 - Bonne réception
dataset1tidy[trad %in% c("réceptionner", "réception", "recevoir", "rassurer", "informer", "confirmer", "document"), theme := 2]
# theme 3 - Manque de document
dataset1tidy[trad %in% c("joindre", "parvenir"), theme := 3]
# association nous + verbe
indNous = dataset1tidy[trad == "nous", , which = T]
indMots = dataset1tidy[trad %in% c("transmettre","envoyer","renvoyer","adresser","communiquer"), , which = T]
indTheme2 = intersect(indNous + 1, indMots)
# association inviter à + verbe
indInviter = dataset1tidy[trad == "inviter", , which = T]
indMots = dataset1tidy[trad %in% c("envoyer","renvoyer"), , which = T]
indTheme2.inter = c(intersect(indInviter + 1, indMots), # e.g. invite envoyer
intersect(indInviter + 2, indMots), # e.g. invite à envoyer
intersect(indInviter + 3, indMots), # e.g. invite à mr/nous envoyer
intersect(indInviter + 4, indMots)) # e.g. invite mr à nous envoyer
indTheme2 = c(indTheme2, indTheme2.inter)
dataset1tidy[indTheme2, theme := 3, with = T]Enfin, on peut supprimer tous les “stop-words” et autres mots parasites.
# suppression des stopwords dans notre jeu de données
dataset1tidy = dataset1tidy[!stopWords, ,on = "trad"]
# suppression des mots "parasites" (1/2)
dataset1tidy = dataset1tidy[! trad %in% rmWord$words]
# suppression des mots parasites (2/2)
dataset1tidy = dataset1tidy[! trad %in% listWord,]L’étape suivante consiste à résumer la présence ou nom d’un thème au sein d’un commentaire. Cette étape permet de “normaliser” la “multi-présence” d’un thème dans un commentaire. Lorsqu’un commentaire est référencé comme abordant plusieurs fois le même thème, on simplifie en disant qu’il aborde qu’une seule fois ce thème. Cela évite les problèmes liés aux mots clés composés de plusieurs mots, e.g “invité à nous transmettre”.
# quels sont les themes abordes par relance ?
themeRelance = dataset1tidy[!is.na(theme), # que les themes différent de NA
.(theme = unique(theme), # les themes abordes
delay = floor(as.numeric(unique(delay)))+1), # le délai arrondi par heure
by = .(relance)] # par relanceEnsuite, on compte le nombre de fois qu’un thème apparait en fonction du délai.
# nombre d'occurrence des themes par délai
themeDelay = themeRelance[, .(freq = .N),
keyby=.(delay, theme)]Regardons dans un premier temps l’évolution du nombre de fois qu’un thème est abordé en fonction du temps qui sépare la date du premier contact et la date d’enregistrement de la relance (i.e. le délai).
ggplot(setkeyv(themeDelay[delay < 7*24,],"delay"),aes(x = delay, y = freq))+
geom_line(aes(col = as.factor(theme)))+
scale_color_manual(values=c("#ebaa28", "#e65005", "#0050aa"))+
scale_y_log10() +
labs(x = "Délai en heures",
y = "Nombre de commentaires",
col = "# du thème")+
theme(legend.position = "top")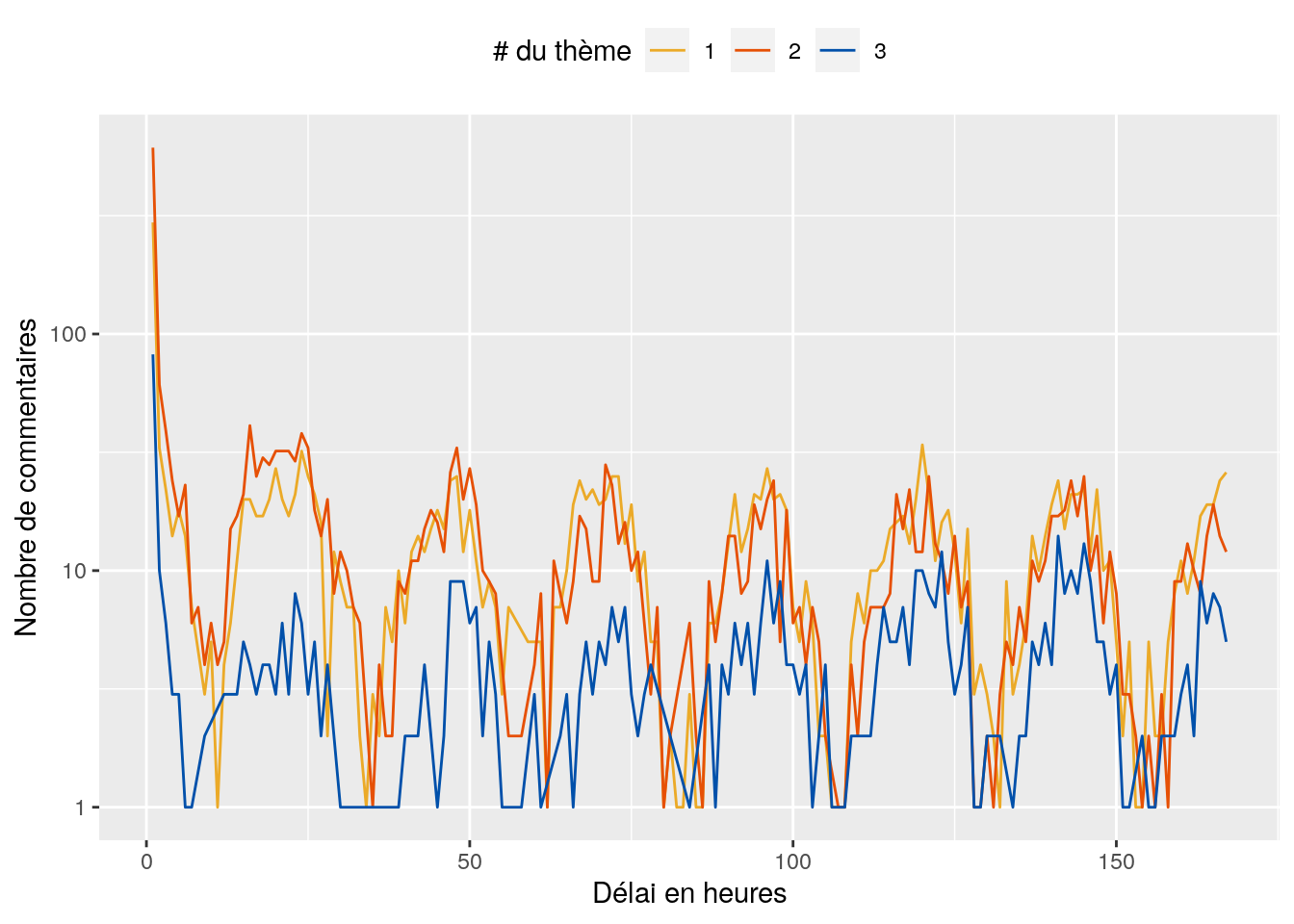
Figure 4.48: Evolution du nombre de commentaires abordant les trois thèmes identifiés en fonction du délai sur une période de 7 jours. Attention à l’échelle en ordonnée, elle est en logarithme base 10.
Bon ici il semble difficile de dégager une tendance en particulier, car les trois courbes sont drivées par la distribution du nombre de commentaires au total. Pour supprimer cet effet et essayer de dégager une tendance globale, on divise le nombre de commentaire abordant l’un des thèmes par le nombre de commentaires au total. Cela permet de travailler en relatif et donc en pourcentage.
# on calcul le nombre de commentaire par délai
relanceDelay = dataset1[,.(delay = floor(as.numeric(delay))+1,
relance = relance)][,.(relance = .N),
keyby=delay]
# on fusionne les deux tableaux pour avoir le nombre de relances totaux et
dataPlot = merge(themeDelay,relanceDelay)
# on calcule le pourcentage de commentaires abordant un thème par délai
dataPlot[, Freq := round((freq/relance)*100,2)]inputPanel(
selectInput("models", label = "Type de modèles :",
choices = c("lm","loess","gam"), selected = "loess"),
sliderInput("periode", label = "Nombre de jour :",
min = 1,
max = floor(dataPlot[,(max(delay))]/24),
value = 7, step = 1),
sliderInput("span", label = "Niveau de \"smooth\" :",
min = 0,
max = 1,
value = 0.75, step = 0.1)
)plotOutput("pourcentDelay")5 For Fun !
# on charge le bon package
library(htmlwidgets)
library(webshot)
library(wordcloud2)
# on construit le bon jeu de données
wordCount = dataset1NVtidy[,.N,by=trad][,.(word=trad,freq=N)]
# le logo
wc = wordcloud2(wordCount,
# figPath = system.file("examples/logo3.png", package = "wordcloud2"),
figPath = "./logo.png",
size = 5,
color ="orange")
saveWidget(wc,"1.html", selfcontained = F)
# le titre
lc = letterCloud(wordCount,
"Malakoff Médéric",
color = "orange",
size = 10)
saveWidget(lc,"2.html",selfcontained = F)
# l'export au format png ne fonctionne pas ici, pour une raison inconnue...
webshot("1.html","1.png",vwidth = 700, vheight = 500, delay = 10)
webshot("2.html","2.png",vwidth = 700, vheight = 500, delay = 10)include_graphics("./images/1.png")
6 Rappels des fonctions utiles
# fonction pour isoler un ou des commentaires en faisant une recherche sur l'un des mots qui le compose
relan = function(txt,nb=1,exact=TRUE){
# indice des commentaires en se basant sur les mots ou leur traduction
if (isTRUE(exact)){
ind = dataset1NVtidy[word==txt,relance]
} else {
ind = dataset1NVtidy[trad==txt,relance]
}
# choix aléatoire des commentaires
if (nb < length(ind)){
ind.random = sample(ind, nb)
} else if (length(ind)!=1){
ind.random = sample(ind, length(ind))
} else {
ind.random = ind
}
# on retourne les commentaires
return(as.list(dataset1NV[relance %in% ind.random, .(commentaire = tolower(COMMENTAIRE_TRT))]))
}